YaaaPS!
Sim, isso mesmo, mais um artigo sobre parameter sniffing! E o que este tem diferente dos demais?
Aliás, o que é YaaaPS?
1. Introdução
Ao procurar a causa de lentidão no processamento de consulta SQL (principalmente naqueles casos em que “no meu computador é rápido mas no banco de dados de produção fica lento”), por várias vezes acabamos encontrando como motivo o parameter sniffing. E assim parameter sniffing virou sinônimo de “coisa ruim”. Mas em essência não é.
Um procedimento é compilado quando é chamado pela primeira vez. Nesse momento, os valores dos parâmetros são coletados (sniffing) e então utilizados pelo otimizador de consulta (query optimizer) para criar o plano de execução sob medida desses valores. Chamadas seguintes ao procedimento geralmente utilizam o plano de execução anteriormente gerado. Esta é a explicação resumida do processo.
Para melhor aproveitamento do conteúdo deste artigo é recomendado conhecer como analisar planos de execução. Se estiver em dúvidas, sugiro a leitura prévia do artigo O Plano Perfeito.
Antes de prosseguir, uma observação. Desenvolver códigos T-SQL exige tempo e dedicação para estudos e testes, afora conhecimento técnico. Sempre que utilizo código T-SQL de outra pessoa como base eu informo o nome do autor e/ou o endereço web da página onde foi publicado, de modo a respeitar o esforço de programação de quem o desenvolveu. Do contrário tem-se o plágio, que além de ser uma violação dos direitos autorais é também uma demonstração de falta de ética profissional. Nesse ponto faço minhas as palavras de Edvaldo Castro e de Erickson Ricci presentes no artigo “PLÁGIO – Sério mesmo?”.
2. Apresentação de casos
O banco de dados utilizado neste artigo é o Adventure Works e para os testes deste artigo foi criado índice pela coluna EndDate:
-- código #2 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com USE AdventureWorks; CREATE nonclustered INDEX IX_WorkOrder_EndDate on Production.WorkOrder (EndDate); go
2.1. Xeretando os parâmetros do procedimento
Como exemplo, vamos considerar o que ocorre com um procedimento com parâmetros quando ele é acionado pela primeira vez, com diferentes valores. O procedimento abaixo lista os produtos que ficaram prontos em determinado período.
-- código #1 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com CREATE PROCEDURE Pedidos_Prontos @dataInicial datetime, @dataFinal datetime as SELECT EndDate, ProductID, OrderQty from Production.WorkOrder where EndDate >= @dataInicial and EndDate < @dataFinal; go
Primeira xeretada. O primeiro teste envolveu o seguinte código SQL:
-- código #3 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com DBCC FREEPROCCACHE; go declare @dataDe datetime, @dataAte datetime; set @dataDe= convert (datetime, '15/5/2014', 103); set @dataAte= convert (datetime, '16/5/2014', 103); EXECUTE Pedidos_Prontos @dataDe, @dataAte; go
A execução de FREEPROCCACHE limpa o cache de planos de execução. Observe que este comando foi rodado em ambiente de testes.
O plano de execução foi o seguinte:

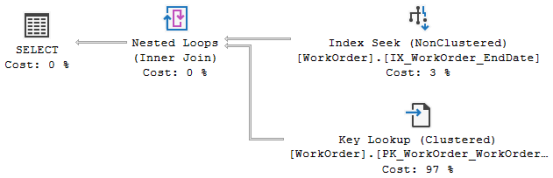
No resultado do procedimento Pedidos_Prontos são exibidas as colunas EndDate, ProductID e OrderQty, sendo que no índice IX_WorkOrder_EndDate somente constam as colunas EndDate e WorkOrderID. Ou seja, o índice não fornece todas as colunas pois não é um índice de cobertura.
A tabela Production.WorkOrder possui cerca de 72 mil linhas. Ao executar o código #3 foi necessário compilar o procedimento Pedidos_Prontos. Como o parâmetro é utilizado na cláusula WHERE,  o valor dele foi obtido (snif) e serviu como fator de decisão para o otimizador de consultas construir o plano de execução fazendo a leitura usando o operador Index Seek e obtendo as colunas faltantes com o operador Key Lookup. Isto ocorreu pois o otimizador de consultas deduziu que o número de linhas a retornar seria reduzido (36, para ser exato), compensando a estratégia adotada.
o valor dele foi obtido (snif) e serviu como fator de decisão para o otimizador de consultas construir o plano de execução fazendo a leitura usando o operador Index Seek e obtendo as colunas faltantes com o operador Key Lookup. Isto ocorreu pois o otimizador de consultas deduziu que o número de linhas a retornar seria reduzido (36, para ser exato), compensando a estratégia adotada.
Segunda xeretada. Ainda com o mesmo procedimento, mas considerando o ano de 2013, como será o plano de execução gerado?
-- código #4 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com DBCC FREEPROCCACHE; go declare @dataDe datetime, @dataAte datetime; set @dataDe= convert (datetime, '1/1/2013', 103); set @dataAte= convert (datetime, '1/1/2014', 103); EXECUTE Pedidos_Prontos @dataDe, @dataAte; go
A execução de FREEPROCCACHE limpa o cache de planos de execução, apagando inclusive o plano de execução anteriormente gerado para o procedimento Pedidos_Prontos.
O plano de execução foi o seguinte:

Novamente temos que ter em mente que no resultado do procedimento Pedidos_Prontos são exibidas as colunas EndDate, ProductID e OrderQty, sendo que no índice IX_WorkOrder_EndDate somente constam as colunas EndDate e WorkOrderID.
Neste segundo exemplo, durante o processo de compilação do procedimento Pedidos_Prontos o otimizador de consulta verificou (snif) ![]() o valor do parâmetro @dataCorte e percebeu que um número elevado de linhas seria retornado: 28.264. Definiu então a estratégia para criação do plano de execução, optando então por ler toda a tabela pelo índice primário.
o valor do parâmetro @dataCorte e percebeu que um número elevado de linhas seria retornado: 28.264. Definiu então a estratégia para criação do plano de execução, optando então por ler toda a tabela pelo índice primário.
Com estes dois exemplos percebemos que o parameter sniffing é, em princípio, um mecanismo de otimização.
2.2. Compilação de procedimento
Na introdução deste artigo foi descrito de forma resumida como é o processo de compilação de um procedimento. Após os exemplos anteriores podemos agora detalhar um pouco mais.
Ao rodar o código #1, que cria o procedimento Pedidos_Prontos, os comandos existentes no procedimento são analisados (parse) com relação à sintaxe. Se um erro de sintaxe for encontrado no corpo do procedimento, uma mensagem de erro é exibida e o procedimento armazenado não é criado. Nesta fase alguns dos objetos (tabelas, por exemplo) não necessitam existir. Entretanto, se os comandos estiverem sintaticamente corretos o texto do procedimento é armazenado na tabela de sistema sys.comments.
Quando o procedimento é executado pela primeira vez, o processador de consulta lê o texto do procedimento na tabela do sistema sys.comments e verifica se agora estão presentes os objetos que não existiam durante a criação do procedimento; este processo é denominado de resolução postergada de nomes (deferred name resolution). Se estiverem ausentes objetos referenciados pelo procedimento quando este for executado, o procedimento deixa de ser executado quando chega ao comando que referencia o objeto ausente e mensagem de erro é exibida. Nesta etapa também são verificadas outras consistências (por exemplo, verificação da compatibilidade de tipo de dados de coluna com variáveis).
Para cada consulta SQL que faça parte do procedimento as estatísticas de distribuição das tabelas presentes na consulta SQL são acessadas e então o otimizador de consulta escolhe a melhor forma de executar a consulta SQL. Observe que somente os valores dos parâmetros são verificados nesse processo, sem qualquer verificação dos valores de variáveis locais (caso existam) ou mesmo qual é o fluxo de processamento dentro do procedimento.
2.3. Quando xeretar não atua
No item anterior foi citado que “sem qualquer verificação dos valores de variáveis locais”. E se existirem variáveis locais que recebam os valores dos parâmetros e com as consultas SQL utilizando o conteúdo das variáveis locais, o que ocorre?
Para responder a essa dúvida, eis o procedimento Pedidos_Prontos modificado para utilizar variável local:
-- código #5 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com CREATE PROCEDURE Pedidos_Prontos_2 @dataInicial datetime, @dataFinal datetime as declare @dataI datetime, @dataF datetime; set @dataI= @dataInicial; set @dataF= @dataFinal; SELECT EndDate, ProductID, OrderQty from Production.WorkOrder where EndDate >= @dataI and EndDate < @dataF; go
Se rodarmos novamente o código #3, mas modificando-o para acionar o procedimento Pedidos_Prontos_2, qual será o plano de execução escolhido pelo otimizador de consulta?
-- código #6 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com DBCC FREEPROCCACHE; go declare @dataDe datetime, @dataAte datetime; set @dataDe= convert (datetime, '15/5/2014', 103); set @dataAte= convert (datetime, '16/5/2014', 103); EXECUTE Pedidos_Prontos_2 @dataDe, @dataAte; go
O número de linhas retornado foi o mesmo, 36 linhas. E nem poderia ser diferente. Mas o modo que o otimizador de consulta escolheu para processar a consulta SQL foi diferente:

Neste terceiro exemplo, durante o processo de compilação do procedimento Pedidos_Prontos o otimizador de consulta não utilizou o mecanismo de parameter sniffing para estimar o número de linhas a retornar,  tendo definido o valor 11.927,9. A partir desse valor definiu então a estratégia para criação do plano de execução, optando então por ler toda a tabela pelo índice primário. E como foi estimado o valor de 11.927,9? No livro “T-SQL Querying”, de Itzik Ben-Gan, encontrei que foi utilizado o valor 16,4317% para estimar o número de linhas a serem lidas, neste caso. Atento que o cálculo de estimativa de linhas varia com a versão do SQL Server, com o nível de compatibilidade do banco de dados e também com o operador de comparação utilizado. Aproveito para mencionar o critério density vector, assunto tratado na terceira parte do artigo “Troubleshooting Parameter Sniffing Issues the Right Way”, de Tara Kizer.
tendo definido o valor 11.927,9. A partir desse valor definiu então a estratégia para criação do plano de execução, optando então por ler toda a tabela pelo índice primário. E como foi estimado o valor de 11.927,9? No livro “T-SQL Querying”, de Itzik Ben-Gan, encontrei que foi utilizado o valor 16,4317% para estimar o número de linhas a serem lidas, neste caso. Atento que o cálculo de estimativa de linhas varia com a versão do SQL Server, com o nível de compatibilidade do banco de dados e também com o operador de comparação utilizado. Aproveito para mencionar o critério density vector, assunto tratado na terceira parte do artigo “Troubleshooting Parameter Sniffing Issues the Right Way”, de Tara Kizer.
Para exibir 36 linhas desta vez toda a tabela foi lida. Na prática o mecanismo de parameter sniffing não atuou, pois nenhum parâmetro foi utilizado diretamente por consulta SQL.
2.4. Quando xeretar atrapalha
E agora chegamos ao caso clássico em que o parameter sniffing é xingado por tornar lento o processamento a consulta. Como citado na introdução, o “procedimento é compilado quando é chamado pela primeira vez” e “Chamadas seguintes ao procedimento geralmente utilizam o plano de execução anteriormente gerado”.
Para encontrar a situação em que o parameter sniffing atrapalha, vamos primeiro rodar o código #4, que emite o relatório para o ano de 2013. A seguir vamos rodar o código #7 abaixo, que é uma versão modificada do código #3 mas sem a limpeza prévia do cache de planos de execução. Ou seja, o plano de execução gerado para o procedimento Pedidos_Prontos será reutilizado, o que é o usual.
-- código #7 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com declare @dataDe datetime, @dataAte datetime; set @dataDe= convert (datetime, '15/5/2014', 103); set @dataAte= convert (datetime, '16/5/2014', 103); EXECUTE Pedidos_Prontos @dataDe, @dataAte; go
O plano de execução do código #7 é o seguinte:

O que aconteceu? Para listar somente 36 linhas toda a tabela Production.WorkOrder foi lida! Este é o caso quando costumamos dizer que a culpa da lentidão é do parameter sniffing.
3. Consertando a casa
A solução para o funcionamento inesperado do parameter sniffing depende de encontrar as causas e avaliar as opções disponíveis.
3.1. Atualizar estatísticas das tabelas
Como mencionado anteriormente, no processo de criação do plano de execução são consultadas as estatísticas de distribuição das tabelas presentes na consulta SQL. Se estas estatísticas estiverem defasadas, então o plano de execução gerado pode não corresponder aos dados existentes na tabela. É possível atualizar manualmente as estatísticas da tabela ao executar o comando
UPDATE STATISTICS tabela with ...
E quando as estatísticas estão defasadas? Ora, quando ainda não foram atualizadas. 😈
Até o SQL Server 2014, inclusive, em geral as estatísticas são atualizadas automaticamente após modificações em 500 + 20% do número de linhas na tabela; os critérios exatos estão no documento Statistical maintenance functionality (AutoStats) in SQL Server. Para tabelas pequenas 20% é um valor pequeno mas imagine uma tabela com 5 milhões de linhas; caso as estatísticas tenham sido atualizadas automaticamente ao atingir esse valor, a próxima atualização será somente quando ultrapassar os 6 milhões de linhas, o que pode gerar probemas de desempenho até que esse novo patamar seja atingido. Uma forma de alterar esse comportamento é ativar o sinalizador (trace flag) 2371, que faz com que o valor percentual se reduza à medida que aumenta o número de linhas da tabela; detalhes no artigo Controlling Autostat behavior in SQL Server.
A partir do SQL Server 2016, inclusive, os critérios de atualização automática variam de acordo com o nível de compatibilidade do banco de dados; detalhes no item AUTO_UPDATE_STATISTICS Option.
Entretanto, dependendo da versão do SQL Server o simples ato de atualizar as estatísticas não garante que o procedimento será recompilado na próxima execução; detalhes no artigo “What caused that plan to go horribly wrong – should you update statistics?”.
3.2. Forçar recompilação do procedimento
É possível forçar que o procedimento seja recompilado na próxima execução ao utilizar o procedimento sp_recompile:
EXECUTE sp_recompile procedure;
Este é um procedimento usual quando temos urgência em resolver o problema, em uma solução imediata e provisória, para após pesquisar as possíveis causas.
Outra forma de forçar a recompilação do procedimento é
EXECUTE procedure with recompile;
Neste último caso o procedimento sempre será recompilado a cada execução. A vantagem é que o melhor plano de consulta será criado cada vez que o procedimento for executado. Entretanto, a compilação é uma operação com uso intenso do processador e pode não ser uma solução ideal para procedimentos que são rodados com freqüência ou em um servidor cujo recurso de processamento esteja elevado.
3.3. Forçar recompilação somente da consulta SQL
No caso de procedimento em que existam várias consultas SQL e que somente em uma delas esteja ocorrendo problemas de desempenho, é possível definir que essa consulta SQL “problemática” seja recompilada a cada execução do procedimento ao adicionar a dica de consulta RECOMPILE. Outro ponto positivo desta opção é que ela permite que o mecanismo de parameter sniffing passe a atuar nos casos em que há variáveis locais recebendo os valores dos parâmetros, conforme exemplificado no item 2.3. Ao criar o procedimento utilizando o código
-- código #8 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com CREATE PROCEDURE Pedidos_Prontos_3 @dataInicial datetime, @dataFinal datetime as declare @dataI datetime, @dataF datetime; set @dataI= @dataInicial; set @dataF= @dataFinal; SELECT EndDate, ProductID, OrderQty from Production.WorkOrder where EndDate >= @dataI and EndDate < @dataF option (recompile); go
e rodar o procedimento Pedidos_Prontos_3 com os valores de @dataDe e @dataAte presentes no código #7:
-- código #9 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com declare @dataDe datetime, @dataAte datetime; set @dataDe= convert (datetime, '15/5/2014', 103); set @dataAte= convert (datetime, '16/5/2014', 103); EXECUTE Pedidos_Prontos_3 @dataDe, @dataAte; go
o seguinte plano de execução é gerado:
Ou seja, o problema que vimos no item 2.3 desapareceu! E o mais interessante é o que consta como predicado de busca neste caso:

Esse mecanismo é denominado de variable sniffing, quando temos a utilização dos valores dos parâmetros como literais no predicado de busca. Como comparação da situação usual eis o predicado de busca do código #3:

Neste caso a consulta SQL será recompilada a cada execução do procedimento. A vantagem é que o melhor plano de consulta será criado cada vez que o procedimento for executado. Entretanto, a compilação é uma operação com uso intenso do processador e pode não ser uma solução ideal para procedimentos que são rodados com freqüência ou em um servidor cujo recurso de processamento esteja elevado.
4. Finalizando…
Há outras soluções, que serão tratadas posteriormente na continuação deste artigo. Entretanto, como introdução ao assunto o artigo me parece bem estruturado e você encontra no capítulo “Material de estudo” sugestões de artigos e vídeos sobre o assunto. Aliás, você pode fazer o curso “Mastering Parameter Sniffing”, de Brent Ozar, por apenas US$ 1.995,00… 😈
Os testes foram realizados inicialmente em instância com SQL Server 2008 (edição Enterprise) e depois repetidos em instância com SQL Server 2016 (edição Developer), o que permitiu observar comportamentos diferentes em algumas situações.
Ah! E YaaaPS é o acrônimo de yet another article about parameter sniffing.
5. Material de estudo
Neste capítulo está relacionado material que utilizei como fonte de consulta e também material adicional que selecionei. Ficam como sugestão de aprofundamento técnico para quem se interessar no assunto “parameter sniffing”.
5.1. Documentação
- CREATE PROCEDURE
- Dica de consulta (hint query)
- FREEPROCCACHE
- Parameter Sensitivity
- sp_recompile
- Statistics
- UPDATE STATISTICS
5.2. Artigos
- Slow in the Application, Fast in SSMS? (Erland Sommarskog)
- Troubleshooting Parameter Sniffing Issues the Right Way (Tara Kizer)
- What caused that plan to go horribly wrong – should you update statistics? (Kimberly Tripp)
5.3. Vídeos
- Identifying and Fixing Parameter Sniffing Issues (Brent Ozar)
5.4. Livros
- T-SQL Querying, de Itzik Ben-Gan. Capítulo 9, Programmable objects, item Stored procedures, páginas 553 a 575

Excelente post José! Esse é um problema bem comum e afeta a performance de vários ambientes. Muitas vezes, os programadores não conhecem esse tipo de problema. Esse post pode ser bem esclarecedor, parabéns!
Abraço,
Luiz Vitor