 Este é o sexto artigo da série sobre como utilizar a linguagem SQL para realizar análise de dados, tratando agora de variância.
Este é o sexto artigo da série sobre como utilizar a linguagem SQL para realizar análise de dados, tratando agora de variância.
1. Introdução
O objetivo desta série de artigos é demonstrar formas de se implementar em SQL os principais conceitos estatísticos. Embora não seja objetivo deste artigo tratar dos conceitos de estatística, ele contém rápida revisão conceitual para a compreensão dos exemplos de programação em sql presentes neste artigo. De qualquer forma recomenda-se a leitura de livros didáticos para quem não tem conhecimentos básicos em estatística.
Na Estatística Descritiva dois tipos de medidas são geralmente utilizadas: a primeira é a que descreve o valor central dos dados observados; e a segunda descreve como elas estão dispersas. Estas medidas são conhecidas como “medidas de tendência central” e “medidas de dispersão”.
Antes de prosseguir, uma observação. Desenvolver códigos T-SQL exige tempo e dedicação para estudos e testes, afora conhecimento técnico. Sempre que utilizo código T-SQL de outra pessoa como base eu informo o nome do autor e/ou o endereço web da página onde foi publicado, de modo a respeitar o esforço de programação de quem o desenvolveu. Do contrário tem-se o plágio, que além de ser uma violação dos direitos autorais é também uma demonstração de falta de ética profissional. Nesse ponto faço minhas as palavras de Edvaldo Castro e de Erickson Ricci presentes no artigo “PLÁGIO – Sério mesmo?”.
2. Distribuição de frequências
3. Medidas de tendência central
4. Medidas de dispersão
As medidas estatísticas de dispersão são utilizadas para mensurar a variação ou dispersão que existe em um conjunto de dados. A utilização dessas medidas possibilita análise mais confiável, visto que as medidas de tendência central (capítulo anterior) muitas vezes escondem a homogeneidade ou não dos dados. Neste capítulo serão tratadas a amplitude total, a variância e o desvio padrão.
4.1. Amplitude total
4.2. Variância
Revisão no conceito. A variância é uma medida de dispersão que indica o quanto os valores de um conjunto variam em relação a um valor médio. Para cada valor calcula-se qual é o desvio em relação à média aritmética: se os desvios forem baixos temos então baixa dispersão mas se esses desvios forem altos, há maior dispersão.
A variância pode ser calculada para todo o conjunto de dados, quando então temos a variância populacional, ou então para uma amostra dos dados, quando temos então a variância amostral.
A fórmula para o cálculo da variância populacional é:

onde N é o tamanho da população e μ é a média aritmética da população.
Quando calculando a variância de uma amostra, a fórmula é

onde X é a média aritmética da amostra. Como exemplo, considerando-se a amostra de valores { 2, 8, 4, 1, 6 }, temos que a média aritmética dessa amostra é

Montando os valores em uma tabela, calculando o desvio individual e elevando esse valor ao quadrado, temos:

A seguir, calculamos a variância para a amostra:
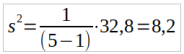
Os dados a analisar podem também estarem em série agrupada com classe simples. Neste caso, são empregadas as seguintes fórmulas para o cálculo de variância:
| população | amostra |
 |
 |
onde Fi representa a frequência para cada valor. Estas duas fórmulas foram aqui mencionadas somente como informação, mas não serão utilizadas.
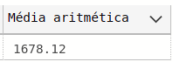
Aplicação. No item 3.1.1 – sobre média aritmética – foi calculado o valor 1.678,12 como a média do ticket médio de compras dos clientes. Considerando-se o ticket médio de cada cliente, qual terá sido a variação do valor do ticket médio em relação à média aritmética?
Vamos inicialmente implementar em sql os passos descritos acima. O primeiro deles é gerar a média aritmética:
-- código #4.1.2 versão 1 -- @ José Diz / Porto SQL -- gera média aritmética da população declare @MediaAritP decimal(12,2); SELECT @MediaAritP= avg (ticketMedio) from #ticketmedio; -- exibe valor calculado SELECT @MediaAritP as [Média aritmética]; -- continua
O resultado da execução desse passo é
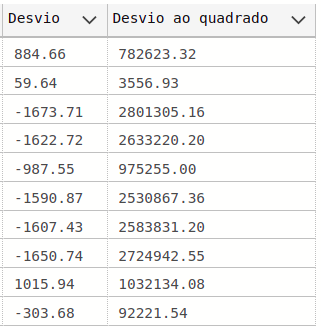
Ainda seguindo os passos descritos na parte conceitual, o próximo passo é montar a tabela intermediária, em que são calculados os desvios individuais em relação à média) e também elevar ao quadrado esse desvio calculado:
-- código #4.1.2 versão 2
-- @ José Diz / Porto SQL
-- gera média aritmética
declare @MediaAritP decimal(12,2);
SELECT @MediaAritP= avg (ticketMedio)
from #ticketmedio;
-- monta tabela intermediária com desvios
SELECT (Ticketmedio - @MediaAritP) as Desvio,
power ((Ticketmedio - @MediaAritP), 2) as DesvioQ
into #tabela2
from #ticketmedio;
-- lista as 10 linhas iniciais, para verificação
SELECT top (10) Desvio, DesvioQ as [Desvio ao quadrado]
from #tabela2;
-- continua
O resultado da execução desse passo é
A seguir, calcular o tamanho da população e, finalizando, o cálculo da variância populacional:
-- código #4.1.2 versão 3
-- @ José Diz / Porto SQL
-- gera média aritmética
declare @MediaAritP decimal(12,2);
SELECT @MediaAritP= avg (ticketMedio)
from #ticketmedio;
-- monta tabela intermediária com desvios
SELECT (Ticketmedio - @MediaAritP) as Desvio,
power ((Ticketmedio - @MediaAritP), 2) as DesvioQ
into #tabela2
from #ticketmedio;
-- calcula tamanho da população
declare @N integer;
SELECT @N= count (ticketmedio)
from #ticketmedio;
-- calcula variância da população
SELECT (sum (DesvioQ) / @N) as [Variância P]
from #tabela2;
O valor da variância populacional é

O código sql acima pode ser otimizado. Por exemplo, o cálculo da média aritmética e da população foram feitos em comandos individuais mas podem ser calculados em um mesmo comando sql, o que reduz a leitura na tabela #ticketmedio. Outra otimização é eliminar a necessidade da tabela intermediária #tabela2, realizando em um único comando: o cálculo do desvio, elevando ao quadrado e somando o total.
-- código #4.1.2 versão 4
-- Autor: José Diz
-- Publicado em: Porto SQL - https://portosql.wordpress.com
-- gera média aritmética e tamanho da população
declare @MediaAritP decimal(12,2), @N integer;
SELECT @MediaAritP= avg (ticketMedio),
@N= count (ticketmedio)
from #ticketmedio;
-- calcula variância da população
SELECT (sum (power ((ticketmedio - @MediaAritP), 2)) / @N) as [Variância P]
from #ticketmedio;
Ficou bem mais simples de programar e o resultado é o mesmo:

Cabe mencionar que no SQL server existem as funções VAR() e VARP(), que calculam as variâncias amostral e populacional, respectivamente. Segue implementação do código sql usando diretamente a função VARP():
-- código #4.1.3 -- @ José Diz / Porto SQL SELECT varp (ticketMedio) as [Variância P] from #ticketmedio;
Bem mais simples de programar. Muito mais simples. 😀
O resultado do código sql #4.1.3 é

Observe a diferença a partir da quarta casa fracionária, em relação ao resultado do código sql #4.1.2:
| #4.1.2 | #4.1.3 |
| 36.416.725,517.369 | 36.416.725,517.866.31 |
Você tem alguma ideia do motivo de tal diferença?
Acesse a versão em PDF para obter a lista de “Material de estudos”, onde estão as referências deste artigo bem como outras sugestões para aprofundamento no assunto.
| Este artigo também está disponível em arquivo no formato PDF, o que possibilita tanto visualizar online quanto obter cópia (download) para leitura offline e até mesmo impressão. Clique no texto abaixo para obter a coletânea de artigos da série, no formato de um e-book. |
