 Sua consulta SQL está lenta como uma lesma?
Sua consulta SQL está lenta como uma lesma?
Por acaso tem cursor no código SQL dela?
Então este artigo é o que você esperava. Ou não…
1. Introdução
Em 2017 comecei a escrever artigo com o título “Quando cursor é a melhor opção”, mas nunca dei prosseguimento ao artigo. Consultando há pouco o esboço, foram escritas 5 páginas e está bem estruturado, demonstrando situações em que a utilização do cursor é/era mais eficiente. É que naquela época ainda havia muitas instalações com a versão 2008 do SQL Server, em que algumas situações podiam ser melhor implementadas utilizando cursor. Entretanto, com o encerramento do suporte à versão 2008 (ocorrido em julho de 2019) aquele artigo perdeu sentido. E então resolvi escrever este artigo, agora sobre como converter códigos T-SQL que utilizem loop (com ou sem cursor) para abordagem mais eficiente. Afinal, várias instalações foram migradas do SQL Server 2008 ou para versão mais recente ou para Azure SQL Database mas talvez continuem com programação T-SQL que utiliza loop.
Há vários passos na migração de instalações 2008 para versão mais recente do SQL Server e o último passo envolve otimizar a programação T-SQL, ao reescrever trechos dos códigos T-SQL utilizando os novos recursos de programação. Sobre esse assunto há algum tempo publiquei o artigo “Novos recursos de programação para SQL Server”, que é uma compilação dos recursos de programação T-SQL implementados da versão 2012 até a versão 2019 do SQL Server. São cerca de 60 páginas em tamanho A4, em arquivo no formato PDF.
Mas qual é o problema em utilizar a cursor?
Antes de prosseguir, uma observação. Desenvolver códigos T-SQL exige tempo e dedicação para estudos e testes, afora conhecimento técnico. Sempre que utilizo código T-SQL de outra pessoa como base eu informo o nome do autor e/ou o endereço web da página onde foi publicado, de modo a respeitar o esforço de programação de quem o desenvolveu. Do contrário tem-se o plágio, que além de ser uma violação dos direitos autorais é também uma demonstração de falta de ética profissional. Nesse ponto faço minhas as palavras de Edvaldo Castro em seu artigo “PLÁGIO – Sério mesmo?”.
2. Abordagem linha a linha e conjunto de linhas
Este capítulo contém demonstração simples das duas abordagens, para compreensão inicial do contexto. A seguinte tabela será utilizada para testes neste artigo:
-- código #2.1 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com CREATE TABLE dbo.Produto ( Chave int not null identity, Cod_Produto char(6) not null, Deno_Produto varchar(30) not null, Valor_Produto money not null, constraint I1_Produto primary key (Chave) );
Há 2 códigos T-SQL de carga da tabela, um utilizando a abordagem linha a linha e outro a abordagem de conjunto de linhas, cada qual descrito nos itens seguintes.
2.1. Abordagem linha a linha
Neste tipo de abordagem, cada linha é processada de forma individual, uma por vez. Esta abordagem geralmente é implementada através loop com while, com o uso ou não de cursor.
O código T-SQL de carga da tabela utilizando a abordagem linha a linha é o seguinte:
-- código #2.2 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com TRUNCATE TABLE dbo.Produto; go declare @I int; set @I= 1; while @I < 90000 begin INSERT into dbo.Produto (Cod_Produto, Deno_Produto, Valor_Produto) SELECT 'T' + right ('0000' + cast ((90000 - @I) as varchar(5)), 5), 'Produto T-' + cast ((90000 - @I) as varchar(5)), ((@I * 10) % 500); set @I+= 1; end; set @I= 1; while @I < 10000 begin INSERT into dbo.Produto (Cod_Produto, Deno_Produto, Valor_Produto) SELECT 'X' + right ('0000' + cast ((10000 - @I) as varchar(5)), 5), 'Produto X-' + cast ((10000 - @I) as varchar(5)), ((@I * 10) % 500); set @I+= 1; end;
Observe que a instrução INSERT é executada uma vez para cada linha incluída. Uma a uma…
O código de atualização utilizando loop é o seguinte:
-- código #2.3 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com declare @Chave int, @Valor_Produto money, @Percentual decimal(5,2); set @Percentual= 0.12; set nocount on; -- lê primeiro produto SELECT top (1) @Chave= Chave, @Valor_Produto= Valor_Produto from dbo.Produto where Cod_Produto between 'T01000' and 'T01999' order by Chave; WHILE @@rowcount > 0 begin -- atualiza preço do produto set @Valor_Produto= @Valor_Produto * (1 + @Percentual); UPDATE dbo.Produto set Valor_Produto= @Valor_Produto where Chave = @Chave; -- lê próximo produto SELECT top (1) @Chave= Chave, @Valor_Produto= Valor_Produto from dbo.Produto where Cod_Produto between 'T01000' and 'T01999' and Chave > @Chave order by Chave; end;
É um procedimento bem simples, somente para demonstração da abordagem linha a linha utilizando loop. Nas implementações que tenho visto de abordagem linha a linha geralmente o processamento é algo mais complicado do que atualização de uma única coluna.
A princípio não seria necessária a variável @Valor_Produto, podendo o cálculo ser realizado diretamente no comando UPDATE:
... UPDATE dbo.Produto set Valor_Produto*= (1 + @Percentual) ...
Entretanto, para fins de simulação de casos do dia a dia, optei por efetuar o cálculo separadamente.
Já com o uso de cursor o mesmo procedimento pode ser implementado da seguinte forma:
-- código #2.4 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com set nocount on; declare @Chave int, @Valor_Produto money, @Percentual decimal(5,2); set @Percentual= 0.12; -- definição do cursor declare Le_Produto CURSOR FAST_FORWARD for SELECT Chave, Valor_Produto from dbo.Produto where Cod_Produto between 'T01000' and 'T01999'; -- inicia o cursor OPEN Le_Produto; -- lê primeiro produto FETCH NEXT from Le_Produto into @Chave, @Valor_Produto; WHILE @@FETCH_STATUS = 0 begin -- atualiza preço do produto set @Valor_Produto= @Valor_Produto * (1 + @Percentual); UPDATE dbo.Produto set Valor_Produto= @Valor_Produto where Chave = @Chave; -- lê próximo produto FETCH NEXT from Le_Produto into @Chave, @Valor_Produto; end; CLOSE Le_Produto; DEALLOCATE Le_Produto;
Procurei declarar o cursor da forma mais simples possível, como tenho visto em vários casos.
As duas formas acima utilizam loop, com a diferença que na segunda a leitura dos dados é realizada através de cursor. Posteriormente veremos como os códigos T-SQL acima podem ser otimizados, ainda no contexto de linha a linha.
2.2. Abordagem conjunto de linhas
Na abordagem de conjunto de linhas a operação é executada uma única vez sobre um conjunto de linhas.
-- código #2.5 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com TRUNCATE TABLE dbo.Produto; go with Tally (N) as ( SELECT row_number() over (order by (SELECT NULL)) from (values (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) as A(n) cross join (values (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) as B(n) cross join (values (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) as C(n) cross join (values (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) as D(n) cross join (values (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) as E(n) ) INSERT into dbo.Produto (Cod_Produto, Deno_Produto, Valor_Produto) SELECT 'T' + right ('0000' + cast ((90000 - T.N) as varchar(5)), 5), 'Produto T-' + cast ((90000 - T.N) as varchar(5)), ((T.N * 10) % 500) from Tally as T where T.N < 90000; with Tally (N) as ( SELECT row_number() over (order by (SELECT NULL)) from (values (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) as A(n) cross join (values (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) as B(n) cross join (values (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) as C(n) cross join (values (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) as D(n) cross join (values (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) as E(n) ) INSERT into dbo.Produto (Cod_Produto, Deno_Produto, Valor_Produto) SELECT 'X' + right ('0000' + cast ((10000 - T.N) as varchar(5)), 5), 'Produto X-' + cast ((10000 - T.N) as varchar(5)), ((T.N * 10) % 500) from Tally as T where T.N < 10000;
Observe que toda a tabela é carregada em uma única execução da instrução INSERT; ou seja, temos um conjunto de linhas a inserir na tabela dbo.Produto. Os valores numéricos são gerados por uma tally table, que é de execução rápida.
Como demonstração simples da abordagem conjunto de linhas, a atualização de preços em toda a tabela de produtos pode ser efetuada da seguinte forma:
-- código #2.6 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com declare @Percentual decimal(5,2); set @Percentual= 0.12; UPDATE dbo.Produto set Valor_Produto*= (1 + @Percentual) where Cod_Produto between 'T01000' and 'T01999';
2.3. Comparativo das estatísticas de execução
Para efetuar a comparação foram acrescentados trechos de código T-SQL.
Carga da tabela de produtos. Há dois códigos T-SQL de carga da tabela, um utilizando a abordagem linha a linha e outro a abordagem conjunto de linhas.
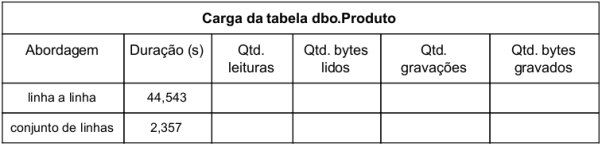
Na coluna de duração, em segundos, observa-se como carga da tabela utilizando a abordagem conjunto de linhas gasta bem menos tempo, com somente cerca de 5,3% do tempo que demora para carregar linha a linha.
Atualização da tabela de produtos. Para a atualização foram efetuados 3 testes, 2 com a abordagem linha a linha e um com a abordagem conjunto de linhas.

Nos testes com abordagem linha a linha observa-se que a construção utilizando cursor (código #2.4) demora menos tempo e que a abordagem conjunto de linhas é bem mais rápida, com certeza. O tempo que demorou para processar utilizando a abordagem linha a linha foi somente de 23,7% do tempo com a abordagem linha a linha, com cursor.
Uma observação adicional: em alguns artigos sobre o uso de cursor li comentários de que o uso de loop com cursor (código #2.4) é mais lento do que loop sem cursor (código #2.3) mas no contexto dos testes deste capítulo percebemos que tal afirmação não pode ser generalizada, pois cada caso é um caso. Aliás, se apagarmos o índice I1_Produto da tabela dbo.Produto é bem possível que loop sem cursor fique ainda mais lento, pois no código #2.3 foi utilizada a coluna Chave para memorizar qual foi a última linha lida e efetuar a próxima leitura de forma rápida, o que somente foi possível por causa do índice existente.
3. O que é o cursor
O modelo relacional utiliza o conceito de uma relação matemática e tem sua base teórica na teoria dos conjuntos e na lógica de predicados de primeira ordem e por isso os operadores relacionais atuam em conjuntos de linhas. Entretanto, há momentos em que os resultados são melhor processados uma linha de cada vez e é justamente para estes casos que a linguagem T-SQL disponibiliza a construção denominada “cursor”, que é a associação de um ponteiro ao conjunto de linhas retornado por um comando T-SQL. O cursor processa uma linha por vez, permitindo operações básicas como excluir, alterar e apagar mas também outras operações de navegação como avançar ou retroceder linha a linha no conjunto de linhas retornado.
No SQL Server há três implementações de cursor mas neste artigo será tratado somente de cursor T-SQL, que são implementados no servidor e gerenciados por comandos T-SQL enviados do cliente para o servidor. Eles podem ser utilizados em jobs, procedimentos ou procedimentos de gatilho (triggers).
Características. O cursor T-SQL possui algumas características, como:
- contexto: informa se o cursor poderá ser utilizado somente no contexto em que foi criado (LOCAL) ou se poderá ser utilizado em outros processos da mesma conexão (GLOBAL);
- navegação: seleciona se o cursor somente poderá ser lido sequencialmente, da primeira à última linha (FORWARD_ONLY) ou se serão permitidas ações como ler para a frente, ler para trás, posicionar (SCROLL);
- atualização: seleciona se as linhas retornadas pelo cursor podem (FOR UPDATE) ou não (READ_ONLY) serem atualizadas;
- visibilidade: controla se atualizações realizadas por outras aplicações no conjunto de linhas apontado pelo cursor serão visualizadas (DYNAMIC) ou não (STATIC) pelo cursor.
Na página DECLARE CURSOR consta a explicação de cada uma dessas características, além de outras.
Modelo típico. O modelo típico de utilização de cursor é:
- definir o cursor, associando-o a um comando que utilize a instrução SELECT (DECLARE CURSOR);
- inicializar a área de trabalho do cursor (OPEN);
- navegar pelo cursor, obtendo o conteúdo de cada linha (FETCH); utilizar o conteúdo da linha (opcionalmente atualizando-a);
- fechar o cursor (CLOSE) e
- liberar o espaço ocupado pelo cursor (DEALLOCATE).
No código #2.4 foi utilizado esse modelo.
Além dos comandos citados anteriormente, há objetos relacionados ao uso de cursor como
e também alguns procedimentos.
4. Convertendo de linha a linha para conjunto de linhas
4.1. Roteiro de análise e conversão
Para converter código em T-SQL da abordagem linha a linha (cursor, por exemplo) para a abordagem conjunto de linhas (set-based) é necessário entender o que o código em T-SQL realiza; não como mas o quê. Há códigos T-SQL que utilizam cursor e que são facilmente convertidos de linha a linha para conjunto de linhas, como a conversão do código #2.4 para o código #2.6 exemplificada no capítulo 2 deste artigo. Nesse caso havia somente uma atualização simples de uma coluna em uma única tabela. Entretanto, muitas vezes o cursor aponta para uma consulta T-SQL que envolve várias tabelas e até mesmo agrupamento de dados. Ou há casos em que há cursor dentro de cursor. Assim, neste capítulo foram analisados outros casos de uso de abordagem linha a linha e como foi a conversão para a abordagem conjunto de linhas.
Análise da leitura. O primeiro passo é analisar como a leitura é realizada. No caso de loop com cursor basta analisar a instrução DECLARE CURSOR mas no caso de loop sem cursor é necessário analisar a leitura da primeira linha (antes de iniciar o WHILE) e a leitura das próximas linhas (geralmente no final do bloco, imediatamente antes da instrução END que finaliza o bloco). Para exercitar essa análise vamos iniciar pelos códigos #2.4 e #2.3.
Na declaração do cursor do código #2.4 há o seguinte comando T-SQL:
declare Le_Produto CURSOR
for SELECT Chave, Valor_Produto
from dbo.Produto
where Cod_Produto between 'T01000' and 'T01999';
São lidas linhas da tabela dbo.Produto, filtrando pela coluna Cod_Produto. Conforme declaração no código #2.1 há índice clustered pela coluna Chave, o que indica que tem-se o operador Clustered Index Scan para efetuar a leitura. Para confirmar isso você pode consultar o plano de execução do código #2.4. Caso não tenha conhecimento em como fazer isso, você pode ler o artigo “O Plano Perfeito”.
Análise do processamento. O segundo passo é analisar qual processamento é realizado com os dados lidos. No caso dos códigos #2.4 e #2.3 o conteúdo da coluna Valor_Produto é multiplicado pelo 1,12 (conteúdo da variável @Percentual somado a 1).
Conversão. A partir das análises é possível então utilizar uma única instrução UPDATE para atualizar as linhas da tabela dbo.Produto, multiplicando o conteúdo da coluna Valor_Produto por 1,12. Ou seja, o resultado da conversão é o código #2.6.
4.2. Caso 2
O segundo caso é o exemplo B que está na documentação de DECLARE CURSOR, que utiliza 2 cursores (um externo e outro interno), para emitir relatório de vendas por vendedor. Para facilitar, copio para cá o código T-SQL do exemplo:
-- código #4.1
USE AdventureWorks2012;
SET NOCOUNT ON;
DECLARE @vendor_id int, @vendor_name nvarchar(50),
@message varchar(80), @product nvarchar(50);
PRINT '-------- Vendor Products Report --------';
DECLARE vendor_cursor CURSOR FOR
SELECT BusinessEntityID, Name
FROM Purchasing.Vendor
WHERE PreferredVendorStatus = 1
ORDER BY BusinessEntityID;
OPEN vendor_cursor;
FETCH NEXT FROM vendor_cursor
INTO @vendor_id, @vendor_name;
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT ' ';
SELECT @message = '----- Products From Vendor: ' +
@vendor_name;
PRINT @message;
-- Declare an inner cursor based
-- on vendor_id from the outer cursor.
DECLARE product_cursor CURSOR FOR
SELECT v.Name
FROM Purchasing.ProductVendor pv, Production.Product v
WHERE pv.ProductID = v.ProductID AND
pv.BusinessEntityID = @vendor_id;
OPEN product_cursor;
FETCH NEXT FROM product_cursor INTO @product;
IF @@FETCH_STATUS != 0
PRINT ' None!';
WHILE @@FETCH_STATUS = 0
BEGIN
SELECT @message = ' ' + @product;
PRINT @message;
FETCH NEXT FROM product_cursor INTO @product;
END;
CLOSE product_cursor;
DEALLOCATE product_cursor;
-- Get the next vendor.
FETCH NEXT FROM vendor_cursor
INTO @vendor_id, @vendor_name;
END;
CLOSE vendor_cursor;
DEALLOCATE vendor_cursor;
que emite o seguinte relatório (trecho inicial)

Para a conversão o primeiro passo é analisar a leitura, que são duas. O primeiro cursor obtém os nomes dos vendedores, além da respectiva identificação na tabela Purchasing.Vendor. A declaração desse primeiro cursor pode ser convertida para a seguinte CTE:
with Consulta1_cursor as ( SELECT BusinessEntityID, Name FROM Purchasing.Vendor WHERE PreferredVendorStatus = 1 ),
Por enquanto bem simples.
O segundo cursor pode ser convertido também para uma CTE:
… Consulta2_cursor as ( SELECT v.Name, pv.BusinessEntityID FROM Purchasing.ProductVendor pv, Production.Product v WHERE pv.ProductID = v.ProductID )
Em relação ao código T-SQL original do cursor foi retirado o filtro
pv.BusinessEntityID = @vendor_id
e acrescentada a coluna pv.BusinessEntityID na lista de colunas. Isto é necessário para substituir o filtro retirado.
A junção entre os vendedores e os produtos vendidos por vendedor é feito através do seguinte código T-SQL:
…
SELECT C1.BusinessEntityID as vendor_id,
C1.Name as vendor_name,
C2.Name as product
from Consulta1_cursor as C1
left join Consulta2_cursor as C2
on C2.BusinessEntityID = C1.BusinessEntityID;
Juntando as partes temos então o conteúdo para a execução da consulta, cujo resultado deve ser formatado diretamente na aplicação:
-- código #4.2 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com with Consulta_cursor_1 as ( SELECT BusinessEntityID, Name FROM Purchasing.Vendor WHERE PreferredVendorStatus = 1 ), Consulta_cursor_2 as ( SELECT v.Name, pv.BusinessEntityID FROM Purchasing.ProductVendor pv, Production.Product v WHERE pv.ProductID = v.ProductID ) SELECT C1.BusinessEntityID as vendor_id, C1.Name as vendor_name, C2.Name as product from Consulta_cursor_1 as C1 left join Consulta_cursor_2 as C2 on C2.BusinessEntityID = C1.BusinessEntityID order by C1.BusinessEntityID;
que emite o seguinte resultado (trecho inicial)

Se analisarmos com atenção o código T-SQL #4.2 percebemos que ele pode ser simplificado para:
-- código #4.3 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com SELECT V.BusinessEntityID as vendor_id, V.Name as vendor_name, P.Name as product from Purchasing.Vendor as V left join Purchasing.ProductVendor as PV on PV.BusinessEntityID = V.BusinessEntityID left join Production.Product as P on P.ProductID = PV.ProductID where V.PreferredVendorStatus = 1 order by V.BusinessEntityID;
Passo a passo foi possível tornar um código T-SQL com abordagem linha a linha e que utiliza 2 cursores para outro código T-SQL, que utiliza a abordagem conjunto de linhas.
É sempre bom verificar se as simplificações são ou não equivalentes; haverá diferença entre os planos de execução gerados para os códigos #4.2 e #4.3? Para dissipar essa dúvida, sugiro que rode os dois códigos T-SQL com a opção de exibir os planos de execução e então compare-os.
E neste caso qual foi o ganho ao converter da abordagem linha a linha para a abordagem conjunto de linhas?

4.3. Caso 3
Este caso analisa código T-SQL postado no tópico “SAP B1 query generator problem” do fórum público da SAP, onde você encontra as informações sobre o autor e o contexto. O código T-SQL é extenso e para não atrapalhar a leitura deste artigo neste item consta uma versão simplificadíssima mas a cópia completa do código T-SQL está no tópico do fórum.
O código T-SQL do cursor é extenso, envolve várias tabelas (a maioria através de subconsultas), agrupamento (me parece que para eliminar repetições, pois não vi funções de agregação diretamente relacionadas com o conteúdo da cláusula GROUP BY).
-- código #4.4
ALTER PROCEDURE [dbo].[MIPLRG23D]
@FrDt as Datetime,
@ToDt as Datetime
AS
BEGIN
create table #temp (
colunas
);
Declare
variáveis para cada coluna de #temp
DECLARE rt_cursor CURSOR FOR
SELECT T0.TransNum, T0.TransType, ...
from OINM T0
where ...
group by T0.TransNum,T0.TransType,T0.ItemCode,
T0.CardName, T0.DocDate, T0.BASE_REF,
T0.InQty, T0.OutQty, T0.DocLineNum
order by T0.DocDate;
SET @Stock = 0;
OPEN rt_cursor;
FETCH NEXT FROM rt_cursor INTO
variáveis exceto @Stock;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @Stock = @Stock + @QuantityReceived - @QuantityIssued;
Insert #temp values
(variáveis
);
FETCH NEXT FROM rt_cursor INTO
variáveis exceto @Stock;
END;
CLOSE rt_cursor;
DEALLOCATE rt_cursor;
End;
go
Se tiver interesse acesse o tópico “SAP B1 query generator problem” e analise o código T-SQL original; o que achou? Percebe-se que é um código T-SQL que necessita ser reescrito e otimizado. Entretanto, considerando-se o objetivo deste artigo, somente a parte de substituir o cursor por uma construção set-based será efetuada.
O que o código T-SQL original faz com o resultado do cursor é uma totalização acumulada (running total) utilizando o conteúdo das variáveis @QuantityReceived e @QuantityIssued. Me parece que o código T-SQL original pode ser alterado para
-- código #4.5 -- Autor: José Diz -- Publicado em: Porto SQL - https://portosql.wordpress.com with -- código T-SQL do cursor transformado em uma CTE rt_cursor as ( SELECT T0.TransNum, T0.TransType, ... from OINM as T0 where ... group by ... ) -- insere as linhas em uma tabela temporária INSERT into #temp (colunas) SELECT colunas exceto a Stock, sum (QuantityReceived - QuantityIssued) over (order by [Posting Date]) as somaStock from rt_cursor;
No código #4.5 o código T-SQL original do cursor, sem a cláusula ORDER BY, é encapsulado na CTE rt_cursor (mesmo nome do cursor para facilitar a compreensão). A seguir, é utilizada a função de janela SUM(), disponível a partir da versão 2012 do SQL Server, para realizar a totalização por data, inserindo então o resultado na tabela #temp.
Aqui uma observação: me parece que a totalização no código T-SQL original não está correta pois no cursor há um agrupamento por algumas colunas (vide código #4.4) mas esse agrupamento é desconsiderado na ordem de leitura, que é somente pela coluna T0.DocDate. Como o objetivo deste artigo é demonstrar a conversão, essa possibilidade foi desconsiderada e a conversão foi literal.
Observe que embora o código T-SQL original seja extenso (e eu o tenha achado confuso), foi possível de forma simples convertê-lo da abordagem linha a linha (row-by-row) para a abordagem conjunto de linhas (set-based).
4.4. Caso 4
Você possui algum caso de código T-SQL que utiliza abordagem linha a linha (com ou sem cursor) e que converteu ou deseja converter para a abordagem conjunto de linhas? Estou à procura de casos interessantes para acrescentar neste artigo e se você tiver algum por favor entre em contato.
5. Fontes de consulta
5.1. Artigos
5.2. Documentação
5.3. Livros
ELMASRI, R; NAVATHE, S. Sistema de banco de dados: 5. ed. São Paulo: Pearson, 2005.
| Este artigo também está disponível em arquivo no formato PDF, o que possibilita tanto visualizar online quanto obter cópia (download) para leitura offline e até mesmo impressão. Clique no texto abaixo para obter o artigo completo. |
