Para melhorar o desempenho de um banco de dados, o que você faria: criaria índices secundários ou desnormalizaria algumas tabelas? Outra solução? Conheça a situação específica descrita neste artigo, avalie prós e contras e diga sua opinião!
1. Introdução
No verbete sobre normalização de dados da wikipedia, na parte em que exemplifica a primeira forma normal (1FN), há o exemplo da entidade Cliente e na qual constam alguns atributos. Um desses atributos, o que se refere aos números de telefones do cliente, é multivalorado. Isto é, possui múltiplos valores:
CLIENTE = {ID, NOME, ENDEREÇO, TELEFONES}
A 1FN informa algo como “os atributos precisam ser atômicos, o que significa que entidades não podem ter valores repetidos e nem atributos possuindo mais de um valor”. Assim, ao aplicar a 1FN na entidade CLIENTE, o verbete menciona que essa entidade é dividida em duas, sendo que a primeira é
CLIENTE = {ID, NOME, ENDEREÇO}
e a segunda é
TELEFONE = {ID_CLIENTE, TELEFONE}
Eu estranhei que no exemplo do verbete da wikipedia conste o atributo ID para cliente, pois essa não é uma informação natural. Isto é, nem toda pessoa possui um “ID”, embora possua nome e geralmente – mas nem sempre – tenha endereço e telefone. Mas, para este artigo não vou me ater aos purismos da modelagem conceitual.
Ao se aplicar a primeira forma normal, atributos multivalorados passam a pertencer a outra entidade, derivada da entidade original. Para fins deste artigo vou utilizar o termo entidade filha e, no modelo físico, de tabela filha. Observe que, no exemplo de normalização acima, a chave de TELEFONE é herdada da chave de CLIENTE.
Ao passar do modelo conceitual para o modelo lógico, define-se um objeto que passa a identificar cada linha de forma única: é a chave primária. Essa escolha pode ser um atributo (ou conjunto de atributos), tendo-se então uma chave natural; ou então a criação de uma nova coluna específica para identificar cada linha de forma única, tendo-se então uma chave substituta.
Há uma linha de projetistas de banco de dados que define o princípio de sempre criar uma chave substituta para cada tabela, de modo a atuar como chave primária na tabela. Mas há outra linha que nos orienta a sempre utilizarmos chaves naturais para as chaves primárias. Enquanto se está no contexto de modelagem lógica, é mais uma escolha pessoal. Entretanto, ao se passar para o modelo físico, é preciso tomar muito cuidado com o uso de chaves substitutas, por causa do processo de indexação. Neste artigo vou me ater somente às tabelas filhas e qual o impacto da abordagem chave substituta versus chave herdada nas tabelas filhas.
Os dois próximos capítulos tratam da implementação de um mesmo conjunto de dados, onde o primeiro utiliza a abordagem de chaves substitutas para definição das chaves primárias (inclusive para tabelas filhas) e o segundo o conceito de chaves herdadas para a definição das chaves primárias nas tabelas filhas.
O capítulo 4, após as apresentações de chaves substitutas e chaves herdadas, contém observações sobre elas.
A seguir, o capítulo 5 trata de assunto que não estava previsto para este artigo mas que, à medida que o texto do artigo era escrito, percebeu-se o quanto seria útil. Apresenta de forma rápida uma técnica utilizada na otimização no desempenho de banco de dados e que envolve desnormalização (processo inverso da normalização) de algumas tabelas.
2. Chave substituta
Para demonstrar as consequências de cada uma dessas opções foram criados dois conjuntos de tabelas, onde um implementa o uso de chave herdada e o segundo implementa o uso de chave substituta, sempre.
Vamos iniciar pela análise de criar tabelas onde a chave primária é uma chave substituta. As tabelas de clientes e de telefones estão com a seguinte estrutura:
-- código #2.1
-- © José Diz / Porto SQL
CREATE TABLE sCLIENTE (
idCliente int not null identity unique,
NomeCliente varchar (80) not null,
Logradouro varchar(50) not null,
Cidade varchar(30) not null,
Estado varchar(30) not null,
CEP char(8) null,
constraint IP_sCLIENTE primary key (idCliente)
);
CREATE TABLE sTELEFONE (
idTelefone int not null identity unique,
Tipo char (1) not null check (Tipo in ('M', 'R', 'T')),
idCliente int not null,
Telefone varchar(20) not null,
constraint IP_sTELEFONE primary key (idTelefone, Tipo),
constraint CE_sTELEFONE_sCLIENTE foreign key (idCliente)
references sCLIENTE
);
A denominação das tabelas inicia com a letra “s” para indicar que é tabela de demonstração do uso de chave substituta. Na tabela sCLIENTE a chave primária é a coluna idCliente, que é uma chave substituta do tipo autonumerada: a cada nova inclusão, o valor é incrementado em 1. O mesmo ocorre na tabela sTELEFONE, em que a chave primária é a coluna idTelefone, que também é uma chave substituta do tipo autonumerada. Assim, as duas tabelas utilizam como chave primária valor que não tem qualquer relação com conteúdo das demais colunas.
Na tabela sTELEFONE existe a coluna idCliente, que é chave estrangeira que aponta para qual cliente pertence o número de telefone. Denominada de CE_sTELEFONE_sCLIENTE, é a forma como foi implementada a relação entre as tabelas sCLIENTE e sTELEFONE, que é 1:N (um cliente pode ter nenhum, um ou mais telefones).
Atenção ao fato de que ambas colunas que estão como chave primária possuem o atributo unique. Isto é porque a propriedade IDENTITY não garante unicidade, isto é, que não haverá valores repetidos.
O conteúdo das tabelas foi carregado a partir de tabelas do banco de dados AdventureWorks. O código sql de carga está ao final deste artigo, no capítulo “Códigos fonte”.
O teste é observar o que ocorre ao listar nome e telefone residencial de determinado cliente.
2.1. Chave substituta como chave primária
O primeiro teste é listar o nome e telefone residencial do cliente cujo valor de idCliente seja 20. O seguinte código sql é utilizado:
-- código #2.2
-- © José Diz / Porto SQL
– lista nome de cliente e telefone residencial do cliente 20
declare @pCod int;
set @pCod= 20;
SELECT C.NomeCliente, T.Telefone
from sCLIENTE as C
left join sTELEFONE as T on T.idCliente = C.idCliente
and T.Tipo = 'R'
where C.idCliente = @pCod;
A junção entre as tabelas sCLIENTE e sTELEFONE é do tipo aberta, isto é OUTER JOIN. É que o cliente pode ou não ter o telefone residencial cadastrado. E, pelo fato do código sql utilizar esse tipo de junção, optou-se por colocar o filtro de tipo de telefone diretamente na cláusula ON: “R” indica telefone residencial.
O que ocorreria se o filtro de tipo de telefone fosse colocado na cláusula WHERE? 🤔
Ao rodar o código sql #2.2, tem-se o seguinte resultado:

e com o plano de execução abaixo:
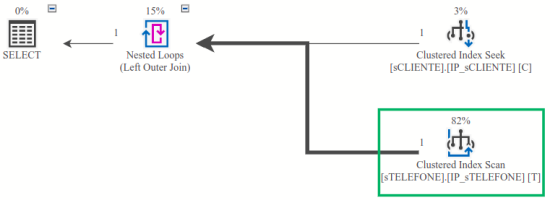
Ora, pelo operador clustered index scan percebe-se que, usando o índice IP_sTELEFONE, toda a tabela sTELEFONE foi lida para se obter uma única linha! Isso é comprovado ao acessar as propriedades desse operador, sendo que na figura abaixo constam quantidade de linhas retornadas e de linhas lidas.

Foram lidas 18.484 linhas (Number of Rows Read) mas somente 1 linha foi utilizada (Actual Number of Rows…) para o fluxo do plano de execução.
Esse é o problema de se utilizar chave substituta como chave primária, em todas as tabelas: o índice primário não implementa a junção natural entre a tabela mãe e a(s) tabela(s) filha(s).
As tabelas acima são pequenas mas imagine se houvessem, por exemplo, 3 milhões de clientes onde cada um tivesse ao menos 1 telefone cadastrado; seriam lidas mais de 3 milhões de linhas na tabela sTELEFONE para retornar um único telefone… Provavelmente o desempenho ficaria sofrível…
2.2. Uso de índice secundário com chave herdada
Para melhorar o desempenho do código sql #2.2 podemos criar um índice secundário na tabela sTELEFONE pela coluna idCliente:
-- código #2.3
-- © José Diz / Porto SQL
-- cria índice secundário na tabela sTELEFONE, coluna idCliente
CREATE unique nonclustered INDEX IS_sTELEFONE
on sTELEFONE (idCliente, Tipo);
Após criar o índice secundário, denominado de IS_sTELEFONE, roda-se novamente o código #2.2. O resultado é o mesmo mas o plano de execução é diferente:
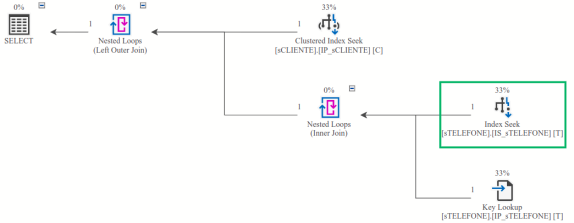
Agora a leitura é feita pelo operador Index Seek, no índice IS_sTELEFONE, e somente uma linha foi lida: bingo! Isso é comprovado ao acessar as propriedades desse operador, sendo que na figura abaixo constam quantidade de linhas retornadas e de linhas lidas.
.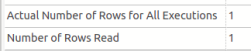
Foi lida uma única linha, conforme se percebe em Number of Rows Read. Ou seja, o novo índice criado agilizou o processo de leitura. Entretanto, apareceu um novo operador, Key Lookup, que não existia no plano de execução anterior; o que é ele e qual o motivo?
Conforme definido no SQL Server Execution Plan Reference (vide capítulo “Material de estudo”), o operador Key lookup is used when another operator is used to find rows that need to be processed, but the index used does not include all columns needed for the query. The Key Lookup operator is then used to fetch the remaining columns from the clustered index.
Mas qual coluna o operador Key Lookup foi buscar no índice primário IP_sTELEFONE?
No índice secundário existe a coluna idCliente, que permite a junção entre as tabelas sCLIENTE e sTELEFONE. Entretanto, a consulta sql necessita retornar também a coluna Telefone. Como ela não está no índice secundário, então o operador Key Lookup busca o conteúdo dessa coluna na linha do cliente, através do índice primário IP_sTELEFONE.
Ou seja, para obter as informações que a consulta necessita, primeiro é obtida uma linha no índice IS_sTELEFONE e depois uma linha na tabela sTELEFONE, através do índice IP_sTELEFONE. São duas linhas da mesma tabela para montar uma única linha.
Ainda não temos a situação ideal, embora seja bem melhor do que a situação tratada no item 2.1.
2.3. Uso de índice secundário com chave herdada e com colunas incluídas
Para evitar o Key Lookup, a opção é acrescentar a coluna Telefone no índice. Isso é possível através da opção INCLUDE. Temos então um terceiro índice para a tabela sTELEFONE, na seguinte forma:
-- código #2.4
-- © José Diz / Porto SQL
-- cria índice secundário na tabela sTELEFONE, coluna idCliente
CREATE unique nonclustered INDEX IS_sTELEFONE_include
on sTELEFONE (idCliente, Tipo)
include (Telefone);
Após criar mais um índice secundário, denominado de IS_sTELEFONE_include, roda-se novamente o código #2.2 e temos então seguinte o plano de execução:
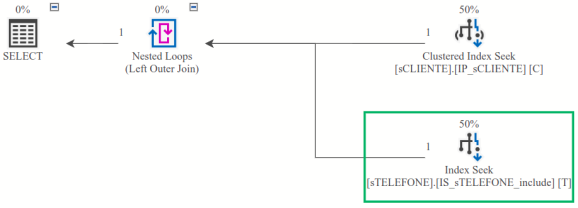
Agora temos a situação ideal: uma única leitura na tabela sCLIENTE e outra leitura única na tabela sTELEFONE (neste caso, através do índice secundário IS_sTELEFONE_include). E temos então uma consulta sql com ótimo desempenho.
Atento que a presença do operador Key Lookup não significa que temos algo negativo no plano de execução, pois depende da quantidade de vezes que ele é executado pelo operador Nested Loops e do quão frequente a consulta sql é rodada diariamente. É preciso sempre analisar o contexto. De qualquer forma, não é assunto deste artigo analisar quando deve-se eliminá-lo.
3. Chave herdada
No capítulo 2 foi utilizada uma consulta sql simples para retornar nome de cliente e respectivo telefone residencial. Vamos repetir o mesmo teste, mas agora nas tabelas que utilizam o conceito de chave herdada.
As tabelas de clientes e de telefones estão com a seguinte estrutura:
-- código #3.1
-- © José Diz / Porto SQL
CREATE TABLE nCLIENTE (
CodCliente int not null,
NomeCliente varchar (80) not null,
Logradouro varchar(50) not null,
Cidade varchar(30) not null,
Estado varchar(30) not null,
CEP char(8) null,
constraint IP_nCLIENTE primary key (CodCliente)|
);
CREATE TABLE nTELEFONE (
CodCliente int not null,
Tipo char (1) not null check (Tipo in ('M', 'R', 'T')),
Telefone varchar(20) not null,
constraint IP_nTELEFONE primary key (CodCliente, Tipo),
constraint CE_nTELEFONE_nCLIENTE foreign key (CodCliente)
references nCLIENTE
);
A denominação das tabelas inicia com a letra “n” para indicar que é tabela de demonstração do uso de chave herdada. Na tabela nCLIENTE a chave primária é a coluna CodCliente, cujo valor é gerado manualmente pelo dono da loja, para cada cliente. Já na tabela nTELEFONE, que é uma tabela filha da tabela de clientes, a chave primária foi herdada da tabela mãe: CodCliente.
Na tabela nTELEFONE a coluna CodCliente atua também como chave estrangeira, apontando para qual cliente pertence o número de telefone. Denominada de CE_nTELEFONE_nCLIENTE, é a forma como foi implementada a relação entre as tabelas nCLIENTE e nTELEFONE, que é 1:N (um cliente pode ter nenhum, um ou mais telefones).
O conteúdo das tabelas foi carregado a partir de tabelas do banco de dados AdventureWorks. O código sql de carga está ao final deste artigo, no capítulo “Códigos fonte”.
O teste é observar o que ocorre ao listar nome e telefone residencial de determinado cliente.
3.1. Chave herdada como chave primária
O primeiro teste é listar o nome e telefone residencial do cliente cujo valor de CodCliente seja 8852, que corresponde a mesma cliente que no código sql #2.2 tinha o valor 20 em idCliente. O seguinte código sql é utilizado:
-- código #3.2
-- © José Diz / Porto SQL
-- lista nome de cliente e telefone residencial do cliente 8852
declare @pCod int;
set @pCod= 8852;
SELECT C.NomeCliente, T.Telefone
from nCLIENTE as C
left join nTELEFONE as T on T.CodCliente = C.CodCliente
and T.Tipo = 'R'
where C.CodCliente = @pCod;
A junção entre as tabelas nCLIENTE e nTELEFONE é do tipo aberta, isto é OUTER JOIN. É que o cliente pode ou não ter o telefone residencial cadastrado. E, pelo fato do código sql utilizar esse tipo de junção, optou-se por colocar o filtro de tipo de telefone diretamente na cláusula ON: “R” indica telefone residencial.
O que ocorreria se o filtro de tipo de telefone fosse colocado na cláusula WHERE? 🤔
Ao rodar o código sql #3.2, tem-se o seguinte resultado:

e com o plano de execução abaixo:
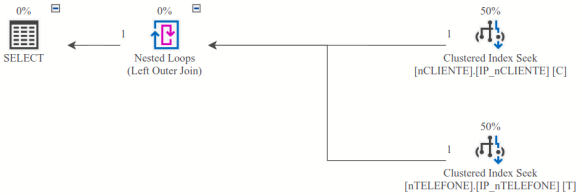
Ao acessar as propriedades do operador Clustered Index Seek, do índice IP_nTELEFONE, temos na figura abaixo as quantidades de linhas retornadas e de linhas lidas.
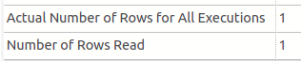
Uma única leitura na tabela nTELEFONE.
4. Observações
4.1. Três índices por tabela filha
No primeiro caso, uso de chave substituta como chave primária na tabela filha, tratado no capítulo 2, observou-se que o desempenho original era ruim. Para resolver o problema de baixo desempenho foi necessário criar índices secundários, tendo a coluna herdada participando da chave do índice secundário e incluindo no índice as demais colunas da tabela.
Já no segundo caso, uso de chave herdada como chave primária na tabela filha, tratado no capítulo 3, não foi necessário criar nada adicional. Teve-se ótimo desempenho com o índice primário existente, sem necessidade de criar índices secundários.
Pergunta que não quer calar: qual o custo da criação dos índices secundários, no primeiro caso?
Na abordagem de chave substituta, para a tabela de telefones foram necessários 3 índices:
-
- índice primário IP_sTELEFONE, tendo as colunas idTelefone e Tipo como chave primária;
- índice secundário IS_sTELEFONE, tendo as colunas idCliente e Tipo como chave;
- índice secundário IS_sTELEFONE_include, tendo as colunas idCliente e Tipo como chave e as demais colunas incluídas como dados do índice.
O primeiro custo adicional é o de manutenção dos índices secundários. Sempre que uma linha for incluída ou apagada da tabela de telefones, a mesma ação terá que ser realizada nos índices secundários. No caso de alteração de valores das colunas que participam de chave de índice secundário, o que geralmente não é usual, os índices secundários terão alteração. Finalizando, sempre que houver alteração no conteúdo de colunas que não façam parte de chave, o mesmo terá que ser feito no índice secundário que possui colunas incluídas.
O segundo custo adicional é o espaço físico necessário para armazenar os índices secundários. Tem-se que o índice secundário que possui colunas incluídas ocupará aproximadamente o mesmo espaço físico que a tabela original. Ou seja, o uso da abordagem de chave substituta mais do que duplica o espaço físico necessário.
Além dos dois fatores mencionados anteriormente, temos ainda que considerar que quanto maior o tamanho do banco de dados, maior é o arquivo de backup do banco de dados.
4.2. Reduzindo o segundo índice secundário
A criação do segundo índice secundário, o que contém colunas incluídas, pode ser não realizada, caso o administrador de banco de dados (dba) assim o decida. A ausência desse índice significa a presença do operador Key Lookup para obter as colunas necessárias, ou o otimizador de consulta pode até optar por uma leitura sequencial pelo índice primário, ignorando completamente o índice secundário que contém somente a coluna herdada (sem colunas incluídas).
Uma técnica para decidir se se cria ou não o índice secundário com colunas incluídas é analisar as consultas custosas (que consomem mais recursos) em que existam key lookup e avaliar quais colunas o operador estava encarregado de buscar. Pode ser que, por exemplo, de 20 colunas existentes na tabela somente 3 ou 4 sejam utilizadas nas consultas custosas, permitindo então criar um índice secundário de colunas incluídas mas com somente parte delas. Este é um trabalho de ajuste fino do índice secundário de colunas incluídas, procurando incluir o mínimo necessário de colunas. Parece simples mas demanda tempo do dba.
5. Desnormalizar para otimizar
Normalização ao extremo no modelo conceitual geralmente acarreta em excesso de tabelas no modelo físico. E isso representa a obrigatoriedade de diversas tabelas serem reunidas (join) na cláusula from, para então obter a informação completa.
Às vezes, para melhorar o desempenho de um banco de dados é comum optar pela desnormalização parcial, em alguns pontos específicos. No nosso caso específico podemos analisar a viabilidade de desnormalizar a informação telefone. O que temos é o registro de números de telefones móvel, residencial e de trabalho dos clientes, sendo registrado no máximo um número para cada tipo de telefone.
Para eliminar a tabela de telefones, podemos criar três colunas de preenchimento opcional na tabela de clientes, uma coluna para cada tipo de telefone. Como suposição, a tabela de clientes passaria a ter a seguinte estrutura:
-- código #5.1
-- © José Diz / Porto SQL
CREATE TABLE dCLIENTE (
idCliente int not null identity unique,
NomeCliente varchar (80) not null,
Logradouro varchar(50) not null,
Cidade varchar(30) not null,
Estado varchar(30) not null,
CEP char(8) null,
TelMovel varchar(20) null,
TelResid varchar(20) null,
TelTrab varchar(20) null,
constraint IP_dCLIENTE primary key (idCliente)
);
Tal estrutura implica na simplificação do código sql de consulta de telefone residencial de cliente, que fica assim:
-- código #5.2
-- © José Diz / Porto SQL
-- lista nome de cliente e telefone residencial do cliente 20
declare @pCod int;
set @pCod= 20;
SELECT C.NomeCliente, C.TelResid as Telefone
from dCLIENTE as C
where C.idCliente = @pCod;
Todas as informações em uma única tabela e o código sql sem necessidade procurar informações adicionais em outra tabela.
A desnormalização, quando em um banco de dados já em uso, traz impactos nas aplicações. No caso deste exemplo, pode-se implementar uma transição, em que no próprio banco de dados é implementada a desnormalização mas ao mesmo tempo a simulação do modelo físico anterior e sem necessidade de duplicidade de dados. Após as aplicações serem reprogramadas, desfaz-se a simulação.
Exemplo de simulação das tabelas sCLIENTE e sTELEFONE, a partir do conteúdo da tabela dCLIENTE:
-- código #5.3
-- © José Diz / Porto SQL
-- apaga estruturas abordagem "substituta"
DROP TABLE IF EXISTS sTELEFONE;
DROP TABLE IF EXISTS sCLIENTE;
go
-- simula tabela sCLIENTE
CREATE VIEW sCLIENTE as
SELECT idCliente, NomeCliente, Logradouro, Cidade, Estado, CEP
from dCLIENTE;
go
-- simula tabela sTELEFONE
CREATE VIEW sTELEFONE as
SELECT 0 as idTelefone, Tf.Tipo, idCliente,
case Tf.Tipo when 'M' then C.TelMovel when 'R' then C.TelResid when 'T' then C.TelTrab end as Telefone
from dCLIENTE as C
cross join (values ('M'), ('R'), ('T')) as Tf (Tipo)
where (Tf.Tipo = 'M' and C.TelMovel is not null)
or (Tf.Tipo = 'R' and C.TelResid is not null)
or (Tf.Tipo = 'T' and C.TelTrab is not null);
O valor da coluna idTelefone ficou zerado, pois não é possível simular o mesmo valor da tabela sTELEFONE. Como a visão não está materializada, não há problema.
Para testar a simulação acima basta rodar novamente o código sql #2.2; observe o plano de execução.
Esta possibilidade, desnormalização, é tratada neste artigo de forma bem superficial e somente para referenciar outra possibilidade de otimização disponível na implementação física de um modelo lógico.
6. Material de estudo
6.1. Artigos
Primary Key Primer for SQL Server
por Phil Factor
6.2. Verbetes de enciclopédias online
7. Códigos fonte
As tabelas utilizadas neste artigo.
7.1. Criação e carga das tabelas
As tabelas foram criadas utilizando o código sql abaixo.
-- código #7.1
-- © José Diz / Porto SQL
-- CONJUNTO 1: utiliza chave natural como chave primária
DROP TABLE IF EXISTS nTELEFONE;
DROP TABLE IF EXISTS nCLIENTE;
CREATE TABLE nCLIENTE (
CodCliente int not null,
NomeCliente varchar (80) not null,
Logradouro varchar(50) not null,
Cidade varchar(30) not null,
Estado varchar(30) not null,
CEP char(8) null,
constraint IP_nCLIENTE primary key (CodCliente)
);
CREATE TABLE nTELEFONE (
CodCliente int not null,
Tipo char (1) not null check (Tipo in ('M', 'R', 'T')),
Telefone varchar(20) not null,
constraint IP_nTELEFONE primary key (CodCliente, Tipo),
constraint CE_nTELEFONE_nCLIENTE foreign key (CodCliente)
references nCLIENTE
);
-- CONJUNTO 2: utiliza chave substituta como chave primária
DROP TABLE IF EXISTS sTELEFONE;
DROP TABLE IF EXISTS sCLIENTE;
CREATE TABLE sCLIENTE (
idCliente int not null identity unique,
NomeCliente varchar (80) not null,
Logradouro varchar(50) not null,
Cidade varchar(30) not null,
Estado varchar(30) not null,
CEP char(8) null,
constraint IP_sCLIENTE primary key (idCliente)
);
CREATE TABLE sTELEFONE (
idTelefone int not null identity unique,
Tipo char (1) not null check (Tipo in ('M', 'R', 'T')),
idCliente int not null,
Telefone varchar(20) not null,
constraint IP_sTELEFONE primary key (idTelefone, Tipo),
constraint CE_sTELEFONE_sCLIENTE foreign key (idCliente)
references sCLIENTE
);
-- CONJUNTO 3: implementa desnormalização no caso de chave substituta
CREATE TABLE dCLIENTE (
idCliente int not null identity unique,
NomeCliente varchar (80) not null,
Logradouro varchar(50) not null,
Cidade varchar(30) not null,
Estado varchar(30) not null,
CEP char(8) null,
TelMovel varchar(20) null,
TelResid varchar(20) null,
TelTrab varchar(20) null,
constraint IP_dCLIENTE primary key (idCliente)
);
Para a carga de conteúdo das tabelas foi utilizado o código sql abaixo, que utiliza tabelas do banco de dados AdventureWorks como fonte.
-- código #7.2
-- © José Diz / Porto SQL
--- Carga das tabelas
DROP TABLE IF EXISTS #clientes;
set nocount on;
SELECT left (concat_ws (' ', P.FirstName, P.MiddleName, P.LastName), 80) as Nomecliente,
left( A.AddressLine1, 50) as Logradouro, left (A.City, 30) as Cidade, left (SP.name, 30) as Estado,
left(A.PostalCode, 8) as CEP, P.BusinessEntityID
into #clientes
from AdventureWorks.Person.Person as P
inner join AdventureWorks.Sales.Customer as C on C.PersonID = P.BusinessEntityID
inner join AdventureWorks.Person.BusinessEntityAddress as r1 on r1.BusinessEntityID = P.BusinessEntityID
inner join AdventureWorks.Person.Address as A on A.AddressID = r1.AddressID
inner join AdventureWorks.Person.StateProvince as SP on SP.StateProvinceID = A.StateProvinceID
where P.PersonType = 'IN'
and r1.AddressTypeID = 2;
-- conjunto 1
TRUNCATE TABLE nTELEFONE;
DELETE from nCLIENTE;
INSERT into dbo.nCLIENTE (CodCliente, NomeCliente, Logradouro, Cidade, Estado, CEP)
SELECT C.BusinessEntityID, C.Nomecliente, C.Logradouro, C.Cidade, C.Estado, C.CEP
from #clientes as C;
INSERT into nTELEFONE (CodCliente, Telefone, Tipo)
SELECT C.BusinessEntityID, Tf.PhoneNumber,
case Tf.PhoneNumberTypeID when 1 then 'M' when 2 then 'R' when 3 then 'T' else '?' end
from #clientes as C
inner join AdventureWorks.Person.PersonPhone as Tf on Tf.BusinessEntityID = C.BusinessEntityID;
-- conjunto 2
DROP TABLE IF EXISTS #clientes2;
SELECT identity (int, 1,1) as idCliente, BusinessEntityID,
C.Nomecliente, C.Logradouro, C.Cidade, C.Estado, C.CEP
into #clientes2
from #clientes as C;
TRUNCATE TABLE sTELEFONE;
DELETE from sCLIENTE;
SET IDENTITY_INSERT sCLIENTE On;
INSERT into dbo.sCLIENTE (idCliente, NomeCliente, Logradouro, Cidade, Estado, CEP)
SELECT idCliente, Nomecliente, Logradouro, Cidade, Estado, CEP
from #clientes2;
SET IDENTITY_INSERT sCLIENTE Off;
INSERT into sTELEFONE (idCliente, Telefone, Tipo)
SELECT idCliente, Tf.PhoneNumber,
case Tf.PhoneNumberTypeID when 1 then 'M' when 2 then 'R' when 3 then
'T' else '?' end
from #clientes2 as C
inner join AdventureWorks.Person.PersonPhone as Tf on Tf.BusinessEntityID = C.BusinessEntityID;
-- conjunto 3
TRUNCATE TABLE dCLIENTE;
SET IDENTITY_INSERT dCLIENTE On;
INSERT into dbo.dCLIENTE (idCliente, NomeCliente, Logradouro, Cidade, Estado, CEP)
SELECT idCliente, Nomecliente, Logradouro, Cidade, Estado, CEP
from #clientes2;
SET IDENTITY_INSERT dCLIENTE Off;
UPDATE C
set TelMovel= case when Tf.PhoneNumberTypeID = 1 then Tf.PhoneNumber end,
TelResid= case when Tf.PhoneNumberTypeID = 2 then Tf.PhoneNumber end,
TelTrab= case when Tf.PhoneNumberTypeID = 3 then Tf.PhoneNumber end
from dbo.dCLIENTE as C
inner join #clientes2 as C2 on C2.idCliente = C.idCliente
inner join AdventureWorks.Person.PersonPhone as Tf on Tf.BusinessEntityID = C2.BusinessEntityID;
| Este artigo também está disponível em arquivo no formato PDF, o que possibilita tanto visualizar online quanto obter cópia (download) para leitura offline e até mesmo impressão. Clique no texto abaixo para obter o artigo completo. |
