 A seguinte dúvida foi postada em grupo de SQL Server no telegram, considerando-se a existência de um relacionamento entre duas tabelas: “…qual seria a diferença em filtrar no relacionamento, ou filtrar no where?”
A seguinte dúvida foi postada em grupo de SQL Server no telegram, considerando-se a existência de um relacionamento entre duas tabelas: “…qual seria a diferença em filtrar no relacionamento, ou filtrar no where?”
1. Introdução
Ao longo de minha atividade com T-SQL, às vezes me deparo com o questionamento de terceiros sobre qual a diferença entre escrever os filtros na cláusula WHERE ou na cláusula ON e também qual dessas formas é mais eficiente. E novamente essa pergunta foi colocada em um grupo de SQL Server, no telegram:
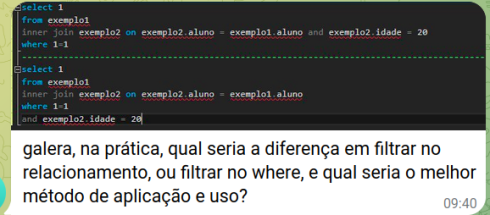
E então decidi escrever este artigo. É claro que ficou semanas somente no campo das ideias, até que começou a tomar e forma e… entrou na lista de tarefas suspensas. Mas então resolvi terminá-lo e espero que ele seja útil.
Antes de continuar, neste artigo é utilizada a expressão “filtro” para indicar os predicados que são utilizados para selecionar o conjunto de linhas a serem processadas. Se tem dúvidas sobre o que é um predicado, a explicação está neste capítulo, mais à frente.
Ao longo deste artigo são analisados vários planos de execução. Caso não tenha o hábito de analisá-los, sugiro a leitura prévia do artigo O Plano de execução Perfeito.
Se você conhece a teoria dos conjuntos, a sintaxe das cláusulas FROM, ON e WHERE, e sabe o que é um predicado, pode saltar direto para o item 1.5, “Ordem lógica e física de processamento”, deste primeiro capítulo.
1.1. Junções na teoria dos conjuntos
Um dos pilares da programação é a teoria dos conjuntos, mas acho que já mencionei isto em algum artigo do Porto SQL. Para não ter que reinventar a roda, sugiro a leitura do artigo Teoria dos Conjuntos.
1.2. Cláusulas FROM e ON
Através destas cláusulas são informadas as tabelas (e outros conjuntos de dados) utilizadas na consulta sql. A sintaxe simplificada destas cláusulas, para os objetivos deste artigo, é
FROM { <joined_table> } [ , ...n ] <joined_table> ::= <table_source> <join_type> <table_source> ON <search_condition> <join_type> ::= [ { INNER | { { LEFT | RIGHT | FULL } [ OUTER ] } } ] JOIN <search_condition> ::= { [ NOT ] <predicate> | ( <search_condition> ) } [ { AND | OR } [ NOT ] { <predicate> | ( <search_condition> ) } ] [ ,...n ]
onde <search_condition> a princípio define a condição a ser atendida para a junção das tabelas. Consultando a documentação sobre <search_condition>, consta que “É uma combinação de um ou mais predicados que usam os operadores lógicos AND, OR e NOT”.
Acesse a documentação completa desta cláusula utilizando a referência que está no capítulo “Material de estudo”.
1.3. Dos predicados…
Mas afinal, o que é predicado?!
<predicate> ::= { expression { = | < > | ! = | > | > = | ! > | < | < = | ! < } expression | string_expression [ NOT ] LIKE string_expression [ ESCAPE 'escape_character' ] | expression [ NOT ] BETWEEN expression AND expression | expression IS [ NOT ] NULL | CONTAINS ( { column | * } , '<contains_search_condition>' ) | FREETEXT ( { column | * } , 'freetext_string' ) | expression [ NOT ] IN ( subquery | expression [ ,...n ] ) | expression { = | < > | ! = | > | > = | ! > | < | < = | ! < } { ALL | SOME | ANY} ( subquery ) | EXISTS ( subquery ) }
Um predicado é um comando ou expressão cujo resultado ou é ou não é. Um exemplo de predicado é Estado = ‘MG’. Ao avaliar um predicado para uma instância de entidade específica (cliente, por exemplo), a expressão representa uma proposição. Suponha que o cliente 43 seja de Aiuruoca (Minas Gerais, MG) e o cliente 42 seja de Janiru (São Paulo, SP). A proposição de que o estado do cliente 42 é igual a Minas Gerais (‘SP’ = ‘MG’) é falsa. Já a proposição de que o cliente 43 é igual a Minas Gerais (‘MG’ = ‘MG’) é verdadeira. Em outras palavras, você pode pensar em um predicado como uma forma geral da proposição mais específica, ou como uma proposição parametrizada. O predicado pode ser verdade para algumas proposições, mas falso para outras.
O modelo relacional baseia-se em predicados para várias finalidades: como uma estratégia de modelagem; para definir a integridade de dados; e para filtrar linhas em consultas. O uso de predicados como uma estratégia de modelagem envolve a listagem de exemplos para proposições que você precisa representar em seu banco de dados, retirando os dados e mantendo os cabeçalhos (predicados) e definindo as relações com base nos predicados. Um exemplo do uso de predicados para impor a integridade de dados ocorre nas restrições CHECK. Exemplos de uso de predicados para filtrar linhas em consultas incluem as cláusulas de consulta ON, WHERE e HAVING que o TSQL suporta.
O que foi explicado resumidamente nos dois parágrafos anteriores sobre predicado e proposição pode ser aprofundado na leitura de livros de lógica matemática ou ainda em verbetes da Wikipedia (neste caso de forma simplificada) tais como: lógica matemática, lógica proposicional, lógica de predicados, proposição, asserção etc. Vide capítulo “Material de estudo”, ao final.
No caso da cláusula WHERE, quando o predicado é sargable o otimizador de consulta pode escolher índice que exista para realizar operações de busca rápida (seek). Caso contrário, pode ocorrer a leitura sequencial (scan) completa no índice (ou na tabela, se não houver índice). Deve-se ter em mente que mesmo que o predicado seja sargable e que exista índice que atenda à cláusula WHERE, ainda assim há outros fatores que o otimizador de consulta analisa para decidir se o índice será ou não utilizado para busca rápida (seek).
No SQL Server um predicado “é”, “não é” ou “não se sabe”. Ou seja, há um terceiro estado: “É uma expressão avaliada como TRUE, FALSE ou UNKNOWN. Os predicados são usados no critério de pesquisa das cláusulas WHERE e HAVING, nas condições de junção das cláusulas FROM e em outras construções em que um valor lógico é necessário”.
1.4. Cláusula WHERE
Esta cláusula é utilizada para definir o filtro a ser aplicado nos conjuntos de dados a serem utilizados na consulta sql.
Na documentação da cláusula WHERE temos a seguinte sintaxe
[ WHERE <search_condition> ]
onde
<search_condition> ::= { [ NOT ] <predicate> | ( <search_condition> ) } [ { AND | OR } [ NOT ] { <predicate> | ( <search_condition> ) } ] [ ,...n ]
sendo que <search_condition>, ou critério de pesquisa, define a condição a ser atendida para que as linhas sejam retornadas. Ou seja, o critério de pesquisa é aplicado no conjunto de linhas. Consultando a documentação sobre <search_condition>, consta que “É uma combinação de um ou mais predicados que usam os operadores lógicos AND, OR e NOT”.
1.5. Ordem lógica e física de processamento
Um comando sql não é executado na mesma ordem em que é escrito, sendo que a ordem lógica de processamento é a seguinte:
-
-
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- SELECT list
- DISTINCT
- ORDER BY
- TOP – OFFSET-FETCH
-
Teoricamente, primeiro é processada toda a cláusula FROM, de acordo com as definições de JOIN e ON. Somente após é que a cláusula WHERE é processada. Isto será útil para compreender o capítulo 2 deste artigo.
Além da ordem lógica de processamento existe a ordem física (ou real) em que o processamento é realizado. Essa ordem está definida no plano de execução, que comanda em qual ordem as tabelas serão lidas; quais métodos de acesso e índices serão utilizados; que algoritmos de junção serão aplicados, etc. Dependendo das condições, filtros da cláusula WHERE podem ser aplicados no momento da leitura da tabela (“FROM”), não seguindo a ordem lógica de processamento descrita no quadro anterior.
No capítulo 1 do livro T-SQL Querying, de Itzik Ben-Gan, há detalhamento do que é o processamento lógico de uma consulta. No capítulo “Material de estudo”, deste artigo, você encontra link para o artigo “Logical Query Processing: What It Is And What It Means to You”, do mesmo autor.
2. Variando a localização do filtro
Este é o capítulo principal deste artigo e demonstra o que ocorre quando aplicamos o filtro nas duas posições, considerando-se junções internas (inner join) e abertas (outer join).
2.1. INNER JOIN
Para o estudo com junções internas – inner join – neste artigo foram utilizadas as tabelas CLIENTE e PEDIDO, cujos códigos sql de criação e carga estão no item 5.1 deste artigo. A tabela CLIENTE contém o nome e o endereço do cliente. Quanto à tabela PEDIDO, ela armazena os pedidos de cada cliente, com a data do pedido e o valor total do pedido. O relacionamento entre as tabelas se dá através da coluna CodCliente, presente nas duas tabelas.
Para demonstração, é solicitada a relação dos pedidos do cliente de número 4484, retornando o nome do cliente, a data e o valor de cada pedido.
-- código #2.1 -- © José Diz / Porto SQL declare @pCod int; set @pCod= 4484; SELECT C.NomeCliente, P.DataPedido as [Data pedido], P.ValorTotal as [Valor pedido] from CLIENTE as C inner join PEDIDO as P on P.CodCliente = C.CodCliente where C.CodCliente = @pCod;
Nesse primeiro código sql, o filtro foi colocado na cláusula WHERE. O resultado da consulta sql é
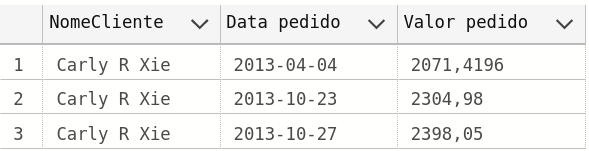
com o seguinte o plano de execução:
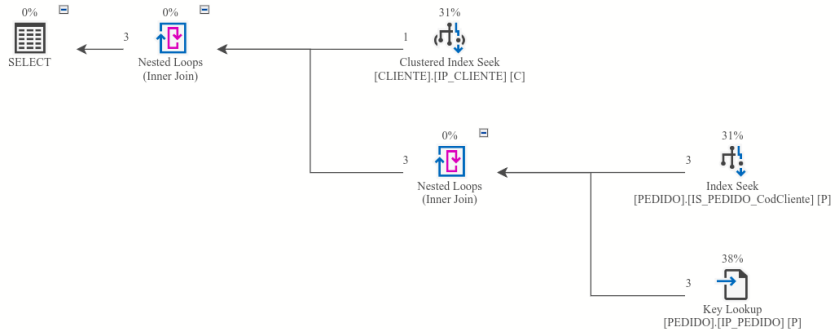
Não sabe o que é predicado? Volte para o capítulo 1 e releia o artigo sem pular itens…
No código sql #2.1 o filtro está na cláusula WHERE e somente para a tabela CLIENTE:
C.CodCliente = @pCod
Entretanto, no plano de execução esse filtro foi aplicado diretamente na leitura das tabelas CLIENTE e PEDIDO, como se percebe nas propriedades dos operadores de leitura das duas tabelas:
Clustered Index Seek em IP_CLIENTE

Clustered Index Seek em IS_PEDIDO_CodCliente

É como se o código sql estivesse escrito assim:
SELECT C.NomeCliente, P.DataPedido as [Data pedido], P.ValorTotal as [Valor pedido] from CLIENTE as C where C.CodCliente = @pCod inner join PEDIDO as P where P.CodCliente = @pCod on P.CodCliente = C.CodCliente;
Quem tomou essa decisão – aplicar o filtro diretamente na leitura das tabelas, antes da junção – foi o otimizador de consulta, no momento de criação do plano de execução e somente após analisar diversas condições. Isto otimiza o processamento da consulta, pois para a junção são encaminhadas somente as linhas de PEDIDO que com certeza correspondam às linhas filtradas de CLIENTE. Melhor do que primeiro fazer as junções e somente após aplicar o filtro, como seria pela ordem lógica de processamento.
A presença do operador Key Lookup se deve pois ao otimizador de consulta, que optou pela utilização do índice IS_PEDIDO_CodCliente e este não possui a coluna ValorTotal. Desta forma, o operador Key Lookup acessa o índice IP_PEDIDO para obter as informações restantes.
A outra opção é colocar o filtro na cláusula ON, onde então temos o seguinte código sql:
-- código #2.2 -- © José Diz / Porto SQL declare @pCod int; set @pCod= 4484; SELECT C.NomeCliente, P.DataPedido as [Data pedido], P.ValorTotal as [Valor pedido] from CLIENTE as C inner join PEDIDO as P on P.CodCliente = C.CodCliente and C.CodCliente = @pCod;
Tanto o resultado quanto o plano de execução são os mesmos do código #2.1.
2.2. OUTER JOIN
Para o estudo com junções abertas – outer join – neste artigo foram utilizadas as tabelas FUNCIONÁRIO e DEPENDENTE, cujo código sql de criação e carga está no item 5.2 deste artigo. A tabela FUNCIONÁRIO contém o código, nome e data de nascimento. Quanto à tabela DEPENDENTE, ela armazena os dependentes dos funcionários e contém nome do dependente, data de nascimento e o código do funcionário de quem é dependente. Há também a idade aproximada, cujo valor é calculado em tempo de exibição.
As tabelas de teste possuem pouquíssimas linhas. A consulta sql básica utilizada neste artigo lista o nome do funcionário, o nome do dependente e a idade aproximada do dependente:
-- código #2.3 -- © José Diz / Porto SQL SELECT F.Nome, D.Nome as Dependente, D.Idade from Funcionário as F left join Dependente as D on D.CodFunc_pai = F.CodFunc;
Como nem todo funcionário possui dependente, a junção entre as tabelas FUNCIONÁRIO e DEPENDENTE é do tipo aberta (outer join).
O código sql retorna o seguinte resultado:
O plano de execução gerado nessa consulta sql é o seguinte:
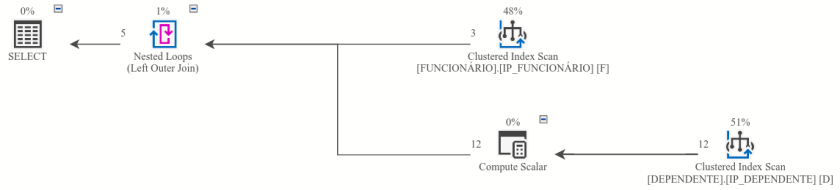
No plano de execução acima, observe que no operador Nested Loops a ação é Left Outer Join.
Em determinado momento, é necessário listar todos os funcionários e também os respectivos dependentes que tenham menos de 12 anos, caso os tenha. Alguém então acrescenta o filtro de idade no código sql da consulta, ficando assim:
-- código #2.4 -- © José Diz / Porto SQL declare @filtro_idade tinyint; set @filtro_idade= 12; SELECT F.Nome, D.Nome as Dependente, D.Idade from Funcionário as F left join Dependente as D on D.CodFunc_pai = F.CodFunc where D.Idade < @filtro_idade;
Observe acima a última linha do código sql, onde foi acrescentado o filtro, através da cláusula WHERE.
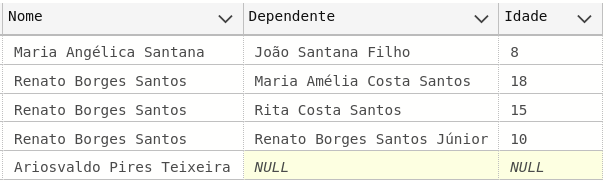
Ao rodar o código sql #2.4, obtemos o seguinte resultado:

Ops! O funcionário “Ariosvaldo Pires Teixeira” não consta do relatório. O que aconteceu?
O administrador de banco de dados (DBA) é chamado e analisa o plano de execução da consulta sql:
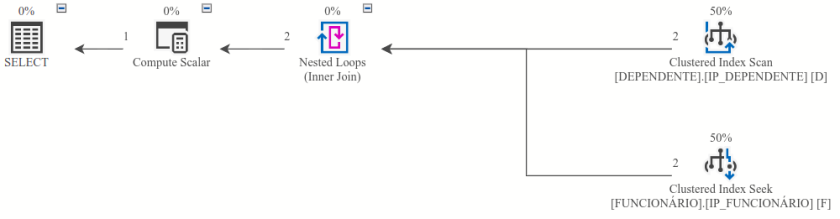
E, analisando meticulosamente o mesmo, depara com algo estranho: no operador Nested Loops a junção consta como inner join embora no código sql esteja left join…

E sugere: “coloca o filtro de idade no ON e vamos ver o que acontece”, sem muita certeza…
O código sql fica então assim, após a sugestão do DBA:
-- código #2.5 -- © José Diz / Porto SQL declare @filtro_idade tinyint; set @filtro_idade= 12; SELECT F.Nome, D.Nome as Dependente, D.Idade from Funcionário as F left join Dependente as D on D.CodFunc_pai = F.CodFunc and D.Idade < @filtro_idade;
Após rodar, o resultado da consulta sql é o seguinte:
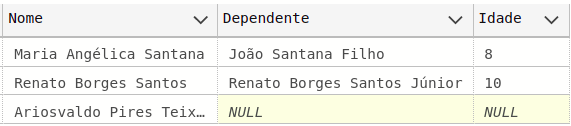
Agora sim o resultado está correto!
Como plano de execução do código #2.5, temos
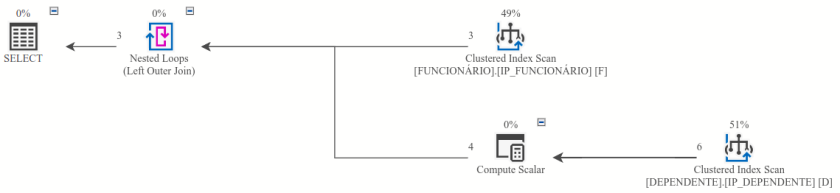
O que então aconteceu no código #2.4, que retornou resultado incompleto?
O otimizador de consulta (vide artigo O Plano de execução Perfeito) procura oportunidades para converter junções abertas (left outer join e right outer join) em junções internas (inner join) sempre que possível. No caso de junções abertas à esquerda (left outer join) essa regra é denominada “A LOJ B -> A JN B”, onde LOJ significa “left outer join” e JN significa “join”. É claro que há condições para que essa conversão ocorra e uma delas é que um predicado intolerante a nulos que referencia colunas das tabelas que fornecem nulos está presente na cláusula WHERE da consulta. Uma vez que este predicado seja intolerante a nulos, qualquer linha totalmente nula que seria produzida pela junção OUTER é eliminada do resultado, tornando a consulta semanticamente equivalente a uma junção interna.
Retornando ao nosso exemplo do código #2.4,
-- código #2.4 -- © José Diz / Porto SQL declare @filtro_idade tinyint; set @filtro_idade= 12; SELECT F.Nome, D.Nome as Dependente, D.Idade from Funcionário as F left join Dependente as D on D.CodFunc_pai = F.CodFunc where D.Idade < @filtro_idade;
o predicado
D.Idade < @filtro_idade
que está na cláusula WHERE não permite que linhas em que a coluna Idade esteja sem informação (isto é, NULL) sejam retornadas. Ou seja, toda linha da tabela FUNCIONÁRIO que não possua ao menos uma linha correspondente na tabela DEPENDENTE é descartada no resultado da consulta. Como isto é a mesma coisa que uma junção interna, o otimizador de consulta substitui LEFT JOIN por INNER JOIN.
Existe um artifício que permite manter o filtro na cláusula WHERE e a junção permanecer left outer join, que é o acréscimo de predicado que possibilite o retorno de linhas da tabela da esquerda e que não tenham correspondentes na tabela da direita, que é informar explicitamente que ausência de valores é aceita. Algo assim:
-- código #2.6 -- © José Diz / Porto SQL declare @filtro_idade tinyint; set @filtro_idade= 12; SELECT F.Nome, D.Nome as Dependente, D.Idade from Funcionário as F left join Dependente as D on D.CodFunc_pai = F.CodFunc where (D.CodFunc_pai is null or D.Idade < @filtro_idade);
Em negrito está o predicado que garante o left outer join.
O critério para definir qual coluna deve constar nesse novo predicado é bem simples: no caso de left outer join, utilizar a coluna da tabela à direita que identifica a junção. No código #2.4 o predicado de junção é
D.CodFunc_pai = F.CodFunc
e a coluna da tabela à direita (DEPENDENTE) é D.CodFunc_pai. Logo, o predicado a adicionar é
D.CodFunc_pai is null or …
Com essa regra de criação de predicado adicional na cláusula WHERE obtém-se o objetivo inicial da consulta sql.
Curiosamente, o plano de execução do código #2.6 é ligeiramente diferente do do código #2.5, embora o resultado obtido seja o mesmo:

Observe a presença do operador Filter, entre os operadores SELECT e Nested Loops. Percebeu o motivo dessa diferença?
3. Conclusão
Padrão. Até certa época eu tinha como orientação que o modelo ideal de aplicação dos predicados seria: predicados de junção no ON e predicados de pesquisa (“filtro”) no WHERE, tendo cuidado com os predicados de pesquisa quando a junção é aberta. Esta regra permite rápida identificação na consulta sql do que é predicado de junção e o que é predicado de pesquisa. Ou seja, facilita a compreensão e manutenção da consulta sql.
-- modelo #3.1: junção interna SELECT colunas from Tabela_1 as A inner join Tabela_2 as B on predicado de junção where filtro;
e
-- modelo #3.2: junção aberta à esquerda SELECT colunas from Tabela_1 as A left join Tabela_2 as B on predicado de junção where (B.coluna is null or filtro em B);
e ainda
-- modelo #3.3: junção aberta à direita SELECT colunas from Tabela_1 as A right join Tabela_2 as B on predicado de junção where (A.coluna is null or filtro em A);
Após algum tempo, e somente para junções abertas (“outer join”), em determinados casos passei a adotar a aplicação dos predicados de pesquisa diretamente na cláusula ON, para não ter que ficar atento à forma indicadas nos modelos #3.2 e #3.3.
Por exemplo, a modificação para o modelo #3.2 passa a ser:
-- modelo #3.4: junção aberta à esquerda SELECT colunas from Tabela_1 as A left join Tabela_2 as B on predicado de junção and filtro em B;
É que às vezes a abordagem não funcionava quando o predicado de junção envolvia múltiplas colunas… Provavelmente eu não percebia algum detalhe e, na pressa de terminar a consulta sql, movia então os predicados de pesquisa da tabela para a cláusula ON. Entretanto, nada impede de usar o filtro sempre na cláusula WHERE (modelos #3,2 e #3,3), desde que acrescente o predicado correto que garanta o outer join, conforme exemplificado no código #2.6.
Observações. O plano de execução do código #2.6 permite novas observações sobre desempenho.

Nele, a presença do operador Filter (na figura acima, circulado na cor laranja) indica que os filtros foram aplicados após a leitura das tabelas, o que coincide com a ordem lógica de processamento descrita no item 1.5. Observe também que, no caso da tabela DEPENDENTE, são retornadas 6 linhas no plano de execução do código #2.5 mas retornaram todas (12) as linhas quando executando o código sql #2.6.
A otimização que ocorreu no código #2.1, com o otimizador de consulta considerando como se o predicado de pesquisa da cláusula WHERE estivesse na cláusula ON, não ocorreu no código #2.6. O que esses 2 planos de execução estão dizendo é que nas junções abertas é mais eficiente colocar os predicados de pesquisa na cláusula ON do que na cláusula WHERE. Será uma regra geral? 🤔
Eu procuro construir códigos sql otimizados mas sem me esquecer do princípio kiss (“keep it simple, stupid!“). Tenho por hábito consultar o plano de execução à medida que desenvolvo consultas sql, analisando possíveis otimizações com alterações mínimas. Entretanto, sempre deve-se ter em mente que um mesmo código sql pode gerar diferentes planos de execução dependendo do conjunto de dados em uso, estatísticas disponíveis, algumas das características do servidor sql, etc.
| Este artigo também está disponível em arquivo no formato PDF, o que possibilita tanto visualizar online quanto obter cópia (download) para leitura offline e até mesmo impressão. Clique no texto abaixo para obter o artigo completo. |
4. Material de estudo
4.1. Artigos
Logical Query Processing: What It Is And What It Means to You
4.2. Documentação
Conversion of outer joins to inner joins
5. Códigos fonte
As tabelas utilizadas neste artigo.
5.1. Tabelas CLIENTE e PEDIDO
As tabelas CLIENTE e PEDIDO foram criadas utilizando o código sql abaixo.
-- código #5.1 -- © José Diz / Porto SQL CREATE TABLE CLIENTE ( CodCliente int not null, NomeCliente varchar (80) not null, Logradouro varchar(50) not null, Cidade varchar(30) not null, Estado varchar(30) not null, CEP char(8) null, constraint IP_CLIENTE primary key (CodCliente) ); CREATE TABLE PEDIDO ( CodPedido int not null, CodCliente int not null, DataPedido date not null, ValorTotal money not null, constraint IP_PEDIDO primary key (CodPedido), constraint CE_PEDIDO_CLIENTE foreign key (CodCliente) references CLIENTE ); CREATE nonclustered INDEX IS_PEDIDO_CodCliente on PEDIDO (CodCliente);
Para a carga de conteúdo das tabelas foi utilizado o código sql abaixo, que utiliza tabelas do banco de dados AdventureWorks como fonte.
-- código #5.2 -- © José Diz / Porto SQL --- Carga das tabelas DROP TABLE IF EXISTS #clientes; set nocount on; SELECT left (concat_ws (' ', P.FirstName, P.MiddleName, P.LastName), 80) as Nomecliente, left( A.AddressLine1, 50) as Logradouro, left (A.City, 30) as Cidade, left (SP.name, 30) as Estado, left(A.PostalCode, 8) as CEP, P.BusinessEntityID into #clientes from AdventureWorks.Person.Person as P inner join AdventureWorks.Sales.Customer as C on C.PersonID = P.BusinessEntityID inner join AdventureWorks.Person.BusinessEntityAddress as r1 on r1.BusinessEntityID = P.BusinessEntityID inner join AdventureWorks.Person.Address as A on A.AddressID = r1.AddressID inner join AdventureWorks.Person.StateProvince as SP on SP.StateProvinceID = A.StateProvinceID where P.PersonType = 'IN' and r1.AddressTypeID = 2; INSERT into dbo.CLIENTE (CodCliente, NomeCliente, Logradouro, Cidade, Estado, CEP) SELECT C.BusinessEntityID, C.Nomecliente, C.Logradouro, C.Cidade, C.Estado, C.CEP from #clientes as C; INSERT into PEDIDO (CodPedido, CodCliente, DataPedido, ValorTotal) SELECT SOH.SalesOrderID, C.PersonID, SOH.OrderDate, SOH.SubTotal from AdventureWorks.Sales.SalesOrderHeader as SOH inner join AdventureWorks.Sales.Customer as C on C.CustomerID = SOH.CustomerID inner join AdventureWorks.Person.Person as P on P.BusinessEntityID = C.PersonID where P.PersonType = 'IN';
5.2. Tabelas FUNCIONÁRIO e DEPENDENTE
As tabelas FUNCIONÁRIO e DEPENDENTE foram criadas utilizando o código sql abaixo.
-- código #5.3 -- © José Diz / Porto SQL -- tabela de funcionários CREATE TABLE dbo.[FUNCIONÁRIO] ( CodFunc int not null, Nome varchar(45) not null, DataNasc datetimeoffset(0) not null ); ALTER TABLE dbo.[FUNCIONÁRIO] ADD CONSTRAINT [IP_FUNCIONÁRIO] primary key clustered (CodFunc); -- tabela de dependentes de funcionários CREATE TABLE dbo.DEPENDENTE ( CodFunc_pai int not null, Nome varchar(45) not null, DataNasc datetimeoffset(0) not null, Idade as cast (datediff (year, DataNasc, sysdatetimeoffset()) as tinyint) ); -- índice primário CREATE clustered INDEX IP_DEPENDENTE on dbo.DEPENDENTE (CodFunc_pai); -- chave estrangeira apontando para a tabela FUNCIONÁRIO ALTER TABLE dbo.DEPENDENTE with check ADD CONSTRAINT [CE_DEPENDENTE_FUNCIONÁRIO] foreign key (CodFunc_pai) references [FUNCIONÁRIO] (CodFunc); ALTER TABLE dbo.Dependente CHECK CONSTRAINT [CE_DEPENDENTE_FUNCIONÁRIO];
Para a carga de conteúdo das tabelas foi utilizado o código sql abaixo.
-- código #5.4 -- © José Diz / Porto SQL set nocount on; -- inclui funcionários INSERT into dbo.[Funcionário] (CodFunc, Nome, DataNasc) values (85418, 'Ariosvaldo Pires Teixeira', '19800305'), (34097, 'Renato Borges Santos', '19701230'), (4027, 'Maria Angélica Santana', '19900731'); -- inclui dependentes INSERT into dbo.Dependente (CodFunc_pai, Nome, DataNasc) values (34097, 'Maria Amélia Costa Santos', '20050130'), (34097, 'Rita Costa Santos', '20081212'), (4027, 'João Santana Filho', '20150304'), (34097, 'Renato Borges Santos Júnior', '20131030');
| Este artigo também está disponível em arquivo no formato PDF, o que possibilita tanto visualizar online quanto obter cópia (download) para leitura offline e até mesmo impressão. Clique no texto abaixo para obter o artigo completo.
Qual é mais rápido: filtros no WHERE ou no ON? |

Parabéns !!! , Artigo muito bom.